Anomalo: The Lighthouse for your Databricks Lakehouse
May 18, 2023
For a modern business, data drives effective decision-making processes. Companies need to store large amounts of data, then efficiently run machine learning and BI analyses against their dataset. In addition, they need to protect their data quality and prevent issues like corrupted or missing data that could skew the results of their models and dashboards.
Proper data architecture will be critical in addressing these needs, and the data lakehouse model is often a great approach. However, even the best data stack can’t stop poor quality data from affecting your business. Read on to find out how you can use the Databricks Delta Lake and the Anomalo data quality platform together to implement a data architecture that’s easy to manage and provides peace of mind.
Delta Lake: Combining data lake + data warehouse for the best of both worlds
Data lakes are popular because they offer low-cost, type-agnostic storage, allowing organizations to collect all their data in a single place. ML tools can take advantage of access to the complete dataset, and many open source technologies work natively with data lakes.
However, the flexibility of data lakes also leads to notable downsides. They don’t work well with most BI tools, as data lakes are not optimized for SQL access. Preserving data quality can also be challenging because of the difficulty of maintaining schemas and the limited observability of data lakes.
To work around these issues, some organizations also use a data warehouse. A data warehouse’s structure and performance optimizations work well with BI and SQL-based tools. However, they don’t support unstructured data like images or sensor data. They also have limited support for ML. To address these issues, teams must often maintain their dataset in a data lake and then move specific tables into their data warehouse for BI use. This setup introduces the opportunity for errors and creates extra costs due to data duplication.
A data lakehouse is a better solution, providing the benefits of a data warehouse on top of an existing data lake. Databricks offers Delta Lake, an open-source storage layer that brings reliability to data lakes while preserving their flexibility. Using Delta Lake, teams don’t have to export their data to a separate, siloed system. In the lakehouse paradigm, a medallion architecture serves all the needs of the team by offering progressively structured layers of data.
Medallion architecture
With Delta Lake’s medallion or “multi-hop” architecture, there are three data quality layers: Bronze, Silver, and Gold. For audits or reprocessing, you can access the raw data at the Bronze layer of the lakehouse. The Silver layer offers data cleaned and conformed “just enough” to represent key business entities and optimize for ingestion. Moving up to the Gold layer, curated and read-optimized business tables support advanced ML and analytics workloads that span your enterprise data, like merging sales and manufacturing data, which would be too costly (or impossible) with a traditional stack.
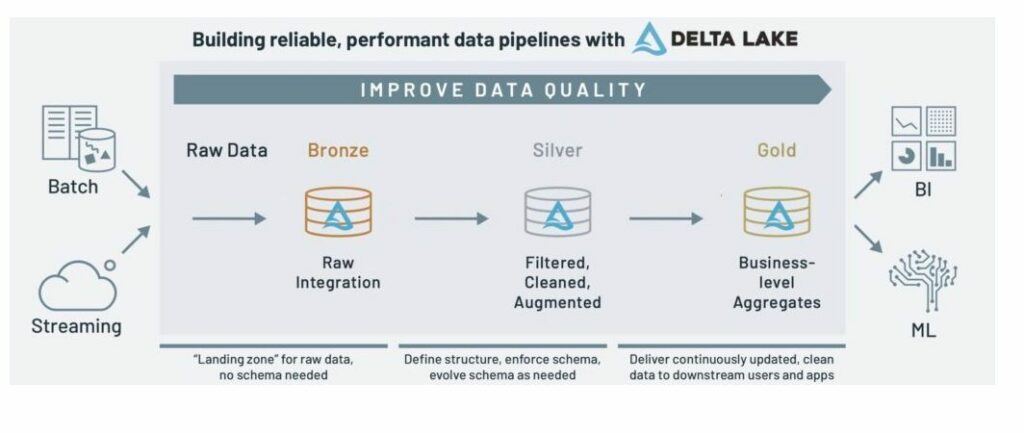
Anomalo: The lighthouse for your lakehouse
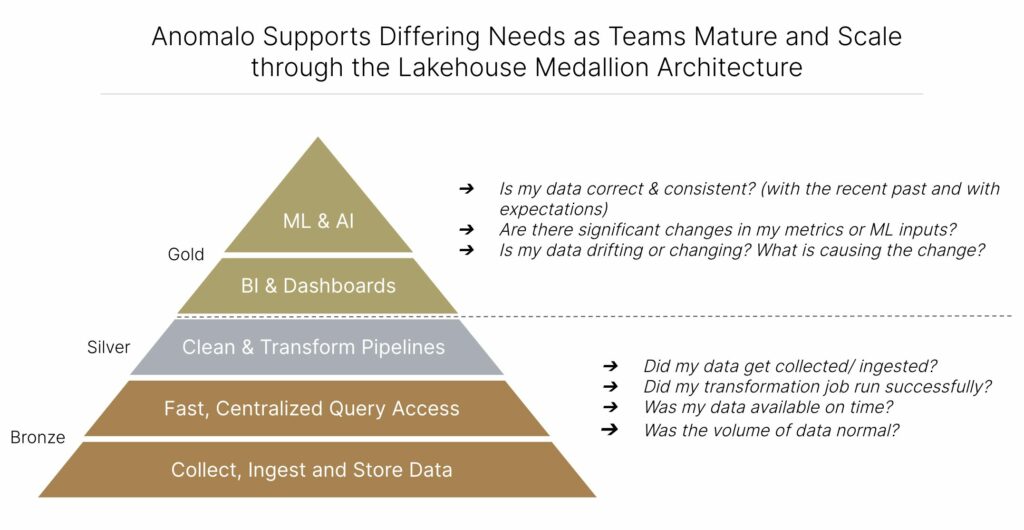
While the medallion architecture ensures that your data is progressively structured and curated, there are limits to this—you might still have issues lurking in the data itself. Stale, corrupted, or missing data prevents businesses from unlocking the full power of their workflows and introducing issues and inaccuracies. Fortunately, when you set up a data lakehouse with Delta Lake, preserving data quality is simple. Databricks customers can use Anomalo, the complete data quality platform, to understand and monitor the health of their data lakehouse.
Anomalo is the only data quality solution that takes full advantage of the power of data lakehouses. The platform uses machine learning to check data quality automatically, offering deep data observability that can even identify unexpected trends within the data itself. Anomalo’s end-to-end monitoring protects every layer of your Delta Lake and allows you to quickly pinpoint the cause of any issues.
For example,as you collect and ingest data at the bronze level, Anomalo can help you answer questions like was my data available on time? As you mature through the Lakehouse architecture though and begin activating data for BI and Analytics at the Gold level, businesses need to detect and resolve complicated data issues, before issues affect BI dashboards and reports or downstream ML models. Anomalo can help answer questions like:
- Is my data correct and consistent, based on the recent past and my expectations?
- Are there significant changes in my metrics?
- Why is my data unexpectedly changing? What is causing these issues?
- Are my ML inputs drifting? Why?
Anomalo is designed to be user-friendly, making it simple for anyone in your organization to use. Its no-code web interface empowers stakeholders to establish continuous monitoring and alerts for the tables they care about. The platform also offers a range of readily-available tools and visualizations to help you drill down to the root of any issues.
In addition, our integration makes it easy to embed Anomalo’s data quality checks directly into your architecture using the Anomalo API for Databricks Workflows. This capability enables users to automatically initiate Anomalo checks and validate whether they have passed or failed before running additional jobs. It has never been easier to integrate Anomalo’s advanced machine learning into your regular workflows. This guarantees a high level of confidence in the data quality across every layer of your stack.
The end-to-end monitoring Anomalo offers for your Databricks lakehouse will build a deeper level of trust in your data and reduce the time spent investigating data issues. Databricks customers can set up a free Anomalo trial plan through Databricks Partner Connect. Follow these steps to see how Anomalo and Databricks can power your decision-making.
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.


Get Started
Meet with our expert team and learn how Anomalo can help you achieve high data quality with less effort.