Beyond dbt Tests: Taking a Comprehensive Approach to Data Quality
March 3, 2023
If you’re using dbt, you have likely come across dbt tests. Used for detecting data quality issues, dbt tests are a set of rules applied to datasets that are used to validate specific conditions, such as column data types, absence of null values, or foreign key relationships. These tests help improve the integrity of each model by making assertions about the results.
While dbt tests are a great first step for data validation, they don’t scale for enterprise use cases. In this post, we’ll discuss the ways dbt tests can be used to protect your data quality, but also why teams can have difficulty scaling them. We’ll then explain how data quality monitoring platforms complement dbt tests to give organizations a deeper understanding of their data quality.
What are dbt tests?
dbt tests are a set of rules that are used for dataset validation, ensuring that the data in a given table or column meet certain criteria. For example, a dbt test might be used to ensure that the column `number_of_tickets` in a table `ticket_sales` is never NULL. The test will look for any failing rows, and if there are none, the test will pass.
dbt tests are useful for testing the integrity of a data model. They work best when you have a defined notion of how data should look and you need to make sure that the data matches that definition. The rules that dbt tests use are easy to understand, which makes them a reliable way to identify data quality issues that have existed from the beginning of a dataset. Additionally, dbt tests are useful for finding violations even when there’s only a small number of them.
For these reasons, dbt tests are often useful to run when making changes to your code, and before or after transformations to ensure the results meet expectations.
Challenges with scaling dbt tests
While dbt tests are a powerful tool for validating some aspects of data quality, enterprises will likely face challenges applying them at scale to use cases like analytics or machine learning. One of the main challenges is that the rules used in dbt tests are rigid. This can lead to situations where your rules are too strict and data is incorrectly flagged as invalid, creating false alarms. Conversely, if your rules are too loose, data quality issues can be missed.
Another challenge is that manually writing rules for dbt tests can quickly become unmanageable. For organizations with thousands of tables and hundreds of thousands of columns, each requiring multiple rules just to enforce the most critical constraints, maintaining dbt tests could be more work than even a full data team could handle.
Adding and updating dbt tests require code changes. The lack of a UI makes it harder for SMEs that aren’t engineers to contribute directly, and may even entirely prevent them from doing so. At the very least, this adds extra work for both SMEs and engineers to translate their understanding into tests.
Data can also change over time, whether unexpectedly or with known seasonality, which means that many rules will have to change as well. This leads to a tradeoff: rules either have to be broad and risk missing issues or rules have to be updated over time as data changes. Trying to maintain a large set of rules can be a significant burden for teams.
Rules can only catch pre-defined issues, so if issues arise that your team didn’t anticipate, you may not get alerted to them. Then, even if you do catch some unexpected issues, dbt tests only provide limited information on the root causes of failures and won’t help you understand important factors like historical variation or seasonality. This can make it difficult to understand why a test has failed and what steps need to be taken to fix the issue.
dbt tests are a useful tool for maintaining data quality and dbt users should be applying them as part of their monitoring strategy, but these scaling challenges also make it necessary for enterprises to add more comprehensive methods to ensure that their data is accurate, reliable, and consistent.
Moving beyond dbt tests
For a modern data-powered organization, dbt tests alone are not enough to protect data quality. Teams need a comprehensive view of their data, with insights into the health and performance of their entire data pipeline. Data quality platforms like Anomalo can provide this with automated monitoring that uses machine learning algorithms to identify anomalies. The same amount of work that lets you configure a source freshness rule in dbt, will give you broad comprehensive coverage of unknown unknown issues in a platform like Anomalo.
The benefits of using a data quality platform like Anomalo allows teams to fill the gaps left by dbt tests. By using ML to understand data rather than requiring you to set strict rules, Anomalo gives you high-quality monitoring that catches more issues while reducing false alarms. Powerful automation also makes it easy to set up comprehensive coverage with just a few clicks.
Anomalo can identify drift within the data and adapt to it, providing more accurate and up-to-date monitoring of data than pre-defined rules can, without requiring heavy maintenance from your team. In addition, providing increased context around failures allows for faster debugging and troubleshooting. Anomalo also makes it easy to set up monitoring of downstream metrics and KPIs, to ensure that every part of your data architecture is working properly. If you’re already using dbt Cloud features like the new dbt Semantic Layer, Anomalo can even automatically monitor the metrics you’ve defined there.
In order to protect all of your data with the minimum amount of effort, the majority of your tests should be through a data quality monitoring platform. Then, for the cases where your data is well understood, you can use rules-based tests to monitor the situation closely. Anomalo can help you visualize the outputs of your dbt tests over time, so you can gain deeper insight to the underlying issues that cause tests to fail, and how often these failures are occurring. We believe there are three pillars of data quality monitoring, validation rules, metric anomalies, and unsupervised data monitoring.
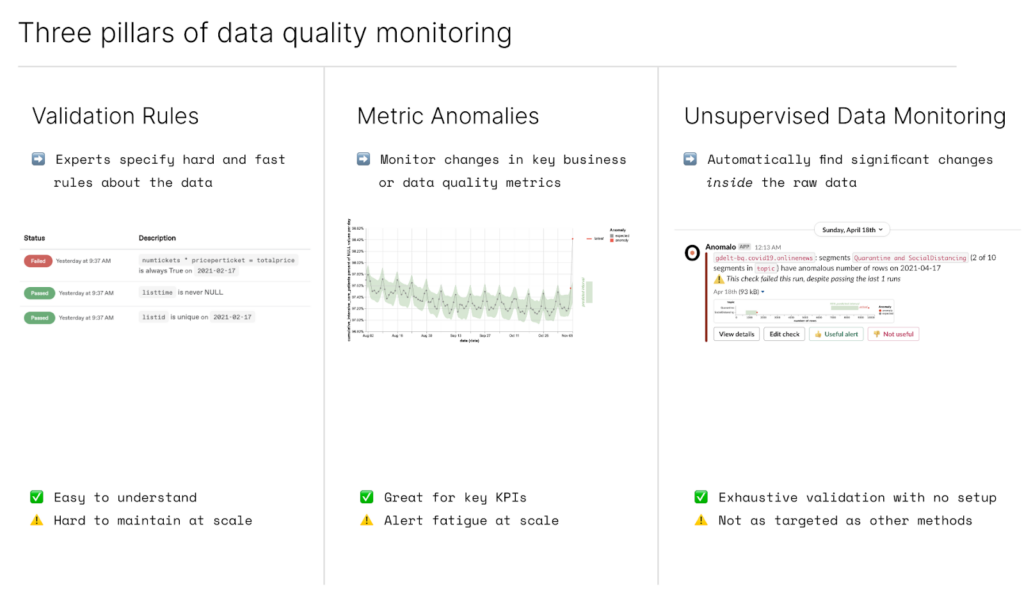
We’re thrilled to see data quality become a key concern in modern data stacks. However, each vendor in your stack will have an individual, isolated view of data quality. Building out a separate solution at each level doesn’t scale, and while it is helpful to protect data quality within each layer, it will only provide narrow views of your data. Enterprises need a dedicated solution like Anomalo to provide a more holistic approach to understanding and maintaining the quality of their data.
If you’re ready to move beyond the basics and get comprehensive monitoring of your organization’s data quality, reach out to us to try a demo of Anomalo today.
Categories
- Product Updates
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Ready to Trust Your Data? Let’s Get Started
Meet with our team to see how Anomalo transforms data quality from a challenge into a competitive edge.