Agents
Elevate Data Accuracy
Data Validation Tools for Accurate Business Insights
Anomalo offers data validation down to the row level for your most important tables, with an easy-to-use UI for adding checks and rich visualizations for triaging issues.
Trusted by Industry Leaders









Data Validation Tool
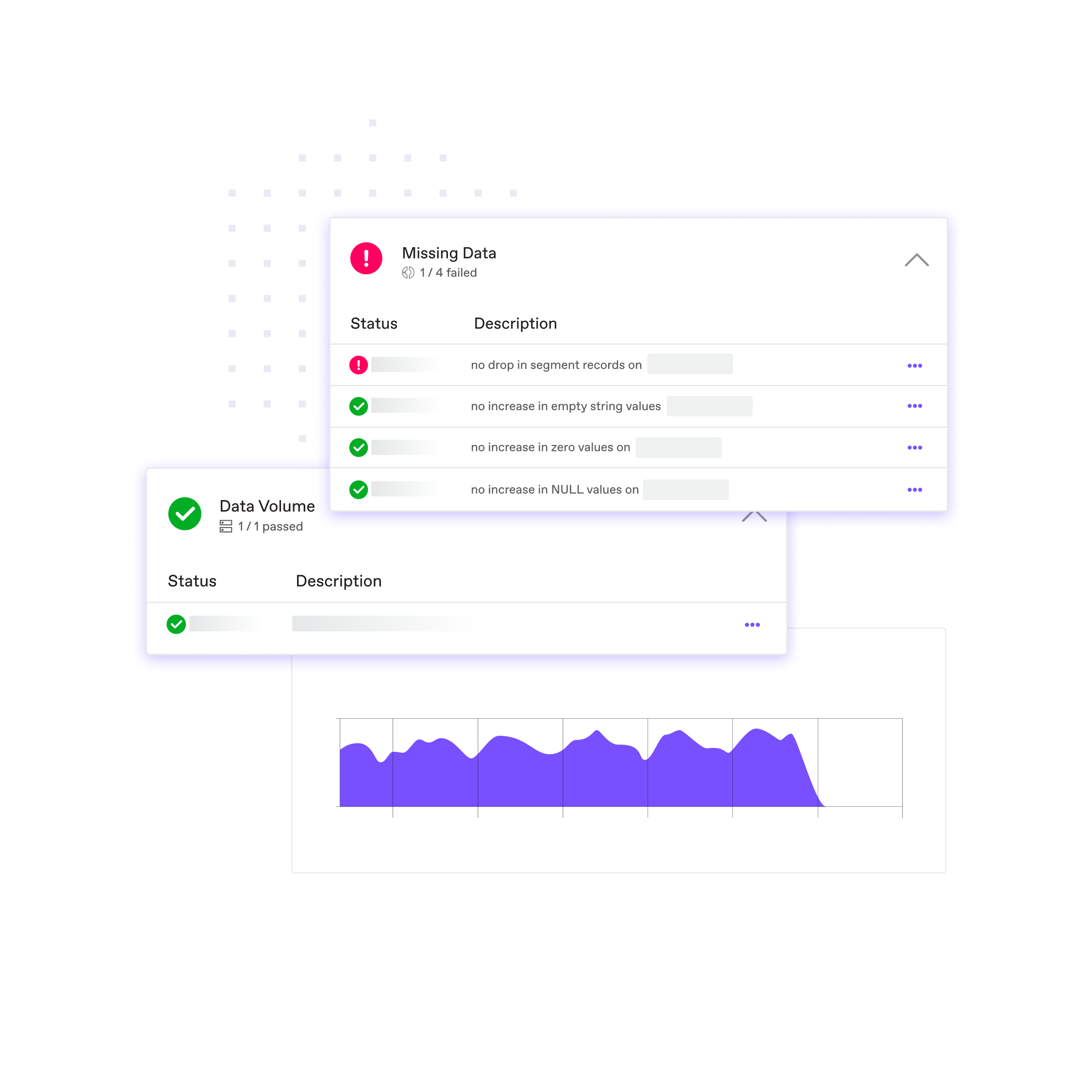
Enforce data integrity with less effort
Automated data quality checks assess accuracy, completeness, consistency, and integrity — without manual setup.
- Detect increases in NULL, zero, or duplicate values
- Pinpoint drops in segment records
- Ensure new data is on time and complete
Data Accuracy
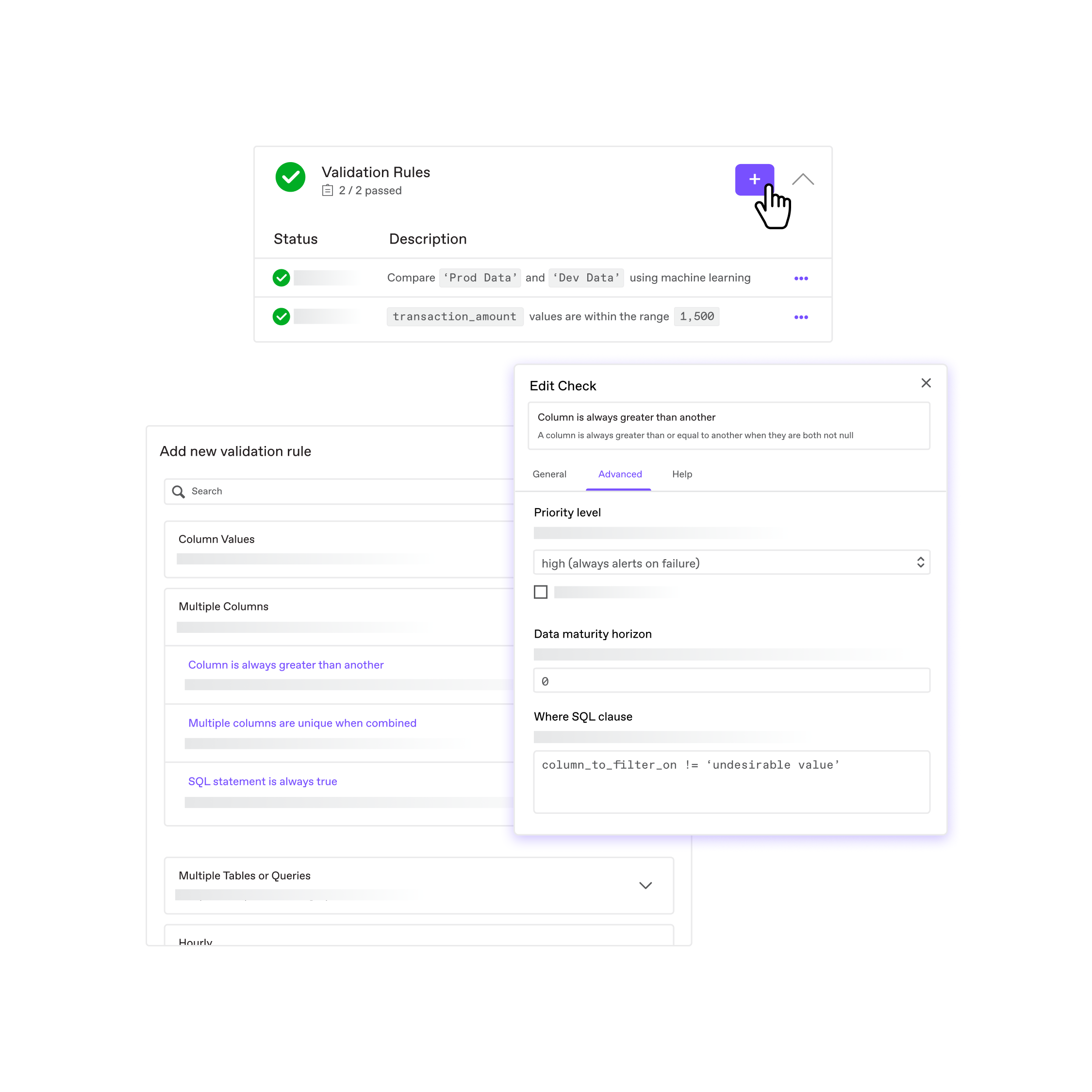
Row-level validation when and where you need it
Easily define checks that ensure data in your key tables is 100% accurate and complies with strict thresholds.
- No-code interface for non-technical users
- Powerful customization with SQL and advanced configuration options
- Migrate your preexisting rules with our API
Data Testing
Integrate with ETL tools to test data pipelines
Validate your data-in-motion to stop pipelines from introducing inaccuracies.
- Plug Anomalo into your DAGs and workflows
- Built-in integrations with Airflow and dbt
- Rich API and Webhook support

Ready to Get Started?
Key Benefits
Data Validation Tools
Automated checks
Cover a wide range of common data quality issues with our built-in validation checks. Simply turn on data quality monitoring for a table and get notified when data is late, incomplete, missing, or anomalous.
Customizable validation rules
We understand how complex your data needs can be, so we offer over 40 kinds of no-code validation checks, plus infinite flexibility in SQL. If you have an edge case, we have an advanced configuration option for it.
Built-in root cause analysis
Go deeper than pass/fail. Anomalo’s visualizations and tools, such as samples of good and bad rows, help you quickly understand the severity of an issue and find the cause of the problem.
Data profiling
Generate a visual profile of your table’s columns, expected values, and historical changes. You can get even more insights by monitoring metrics about your data and its key segments.
FAQ
Frequently Asked Questions
If you have additional questions, we are happy to answer them.
How often does Anomalo run data validation checks?
Anomalo checks to see if new data has arrived on a daily basis, starting at midnight. After the data freshness check passes, Anomalo’s data volume check runs every hour to see if the data is completely loaded into the table. Then, all other checks are run asynchronously after the data volume check passes.
While this scheduling is designed to be cost-effective and reduce noisy notifications, you can modify it if you need. This is useful if you want to run a specific check on a set schedule, regardless of how the table is configured or whether the data in the table is fresh.
What types of data validation tests does Anomalo perform?
Anomalo offers a variety of data validation testing techniques. We provide four categories of checks in the data validation process:
- Data freshness: Checks if new data has arrived on time
Data volume: Checks if new data is complete
Missing data: Looks for drops in segment records, increases in NULL values, or increases in zero values
Table anomalies: Runs Anomalo’s AI-based anomaly detection to find anomalous records, and also checks for increases in duplicate data for columns that previously contained unique records
Beyond this, you can choose from 40+ kinds of user-defined validation rules in the Anomalo UI. Data engineers can write custom checks with SQL and even run them programmatically using Anomalo’s API.
How customizable are the validation rules within Anomalo?
Very customizable! If you need to set up a rule for validating data in Anomalo, you can use our no-code UI or integrate with our API. Within the no-code UI, there are over 40 checks that each allow you to specify a range of thresholds, options, and constraints. When defining a check in the UI, you can enter a custom SQL query at any time if you don’t see the options you’re looking for. Additionally, the API provides nearly limitless capabilities for specifying validation checks in code.
Does Anomalo support integration with different data sources?
Anomalo offers one-click integrations with all major data warehouses/lakes/lakehouses. You can also run Anomalo’s checks as part of your ETL pipeline via our integrations with orchestration tools like Airflow and dbt. Additionally, you can connect Anomalo to a data catalog like Alation to ensure that the results of data validation checks are accessible to all business users.
What reporting and visualization features does Anomalo provide?
Anomalo offers dozens of visualizations to bring you more insight into why a check might be passing or failing, as well as a high-level executive dashboard that visually tracks data quality progress and highlights problem areas across your entire data warehouse. A few specific features to highlight are our root causes analysis and data lineage tools. Our root cause analysis feature creates a severity report of each incident and lets you pull samples of good and bad rows to dig into the issue further. Our data lineage tools map out upstream and downstream tables to create a better understanding of how data assets move through your system. Additionally, our comprehensive validation features ensure that the correct data is captured and maintained throughout your workflows, helping to detect anomalies and inconsistencies before they affect business outcomes.
What algorithms does Anomalo utilize for anomaly detection?
Anomalo uses unsupervised anomaly detection techniques. Taking on a sample of 10,000 records from the most recent data and comparison samples from previous days, our machine learning algorithms will search for ways that the existing dataset is different from those previous days. If detected changes are above a dynamically adjusted threshold, which is based on the historical data “chaos” or levels of fluctuation in the data, this check will fail.
How much time do Anomalo’s models need to learn about my data?
Anomalo provides an automated and repeatable solution to validate data entry and monitor data movement processes. The machine learning algorithms need to run for 2 weeks to produce useful results. Results will continue to improve over the next 30–60 days. When a table is newly configured, the dynamically-adjusted threshold will be set to the maximum score, which requires anomalies to be extreme. Gradually, the threshold will decrease as the anomaly detection algorithms learn the expected chaos for the table.
How does Anomalo’s root cause analysis help me understand anomalous data points?
With automated root cause analysis, you can download a sample of a “good” and “bad” data point every time Anomalo flags an issue. Anomalo also will highlight the columns and data segments that contain the largest portions of anomalous data points, compared to normal data. These tools and visualizations will help you pinpoint the anomaly in your data.
Ready to Trust Your Data? Let’s Get Started
Meet with our team to see how Anomalo transforms data quality from a challenge into a competitive edge.