Data Anomaly: What Is It, Common Types and How to Identify Them
May 30, 2024
What is an Anomaly?
In today’s data-driven world, organizations rely heavily on the accuracy and reliability of their datasets to make informed decisions and drive business success. However, the presence of data anomalies can significantly undermine the integrity of these datasets, leading to flawed conclusions and suboptimal outcomes. A data anomaly is any deviation or irregularity in a dataset that does not conform to expected patterns or behaviors. These anomalies can manifest in various forms, such as outliers, unexpected patterns, or errors.
The importance of detecting and addressing data anomalies cannot be overstated. Data quality issues can have far-reaching consequences, impacting decision-making processes across various industries. Data anomalies can compromise the integrity of the data, leading to erroneous conclusions, flawed predictions, and ultimately, poor business decisions.
In this blog post, we will delve into the world of data anomalies, exploring their different types and the methods used to identify them. By understanding the nature of these anomalies and employing effective detection techniques, organizations can proactively identify and address data quality issues, ensuring the reliability and usefulness of their datasets. We will also discuss the importance of data quality and how it affects various aspects of an organization’s operations, from financial reporting to customer experience.
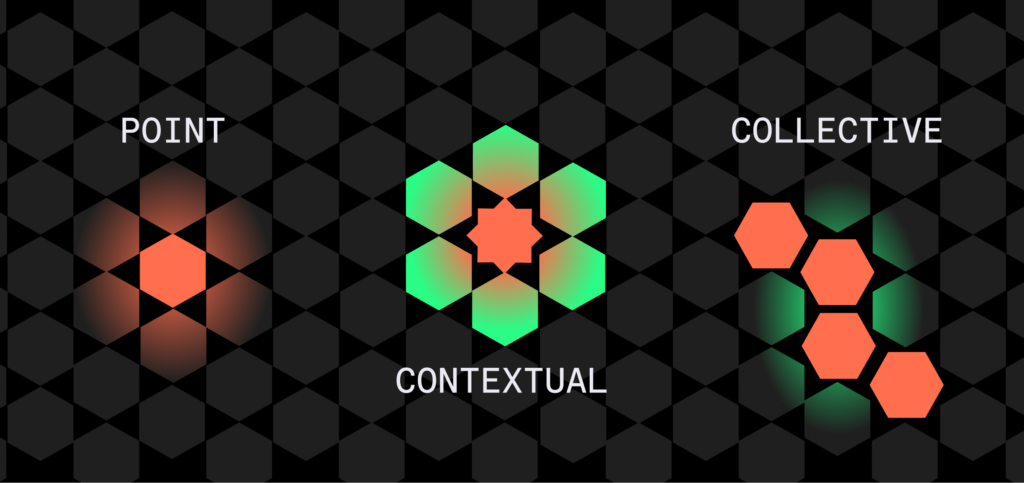
There are three main types of anomalies: point anomalies, contextual anomalies, and collective anomalies. Point anomalies, also known as outliers, are individual data points that deviate significantly from the rest of the dataset, often signaling errors or rare events. Contextual anomalies are data points that are unusual in a specific context but may appear normal in another. These anomalies are context-dependent and are often seen in time-series data, where a value might be expected under certain conditions but not others. Collective anomalies, on the other hand, occur when a collection of related data points deviate collectively from the norm, even if individual points within the group do not seem anomalous on their own. Recognizing these distinct types of anomalies is essential for effective data analysis, as each type requires different detection methods and has unique implications for interpreting the data.
Common Types of Data Anomalies
Point Anomalies (Outliers)
Point anomalies, also known as outliers, are data points that significantly differ from the rest of the dataset. These anomalies can be classified into two subcategories:
- 1. Univariate outliers: These are deviations from the norm within a single data set. For example, in a sales database, a customer age of 150 would be considered a univariate outlier. Such anomalies can be easily identified by examining individual data points and comparing them to the expected range or distribution of values within the dataset.
- 2. Multivariate outliers: These anomalies are identified by considering multiple variables together. For instance, a purchase with an unusually high quantity of a rarely bought item together would be a multivariate outlier. Detecting multivariate outliers requires a more complex analysis that takes into account the relationships and correlations between different variables.
Point anomalies can be identified using various statistical methods and visualization techniques:
- Z-scores: By calculating standard deviations, outliers that fall outside a specific range (e.g., 3 standard deviations from the mean) can be identified. This method is particularly useful for identifying univariate outliers and helps in understanding the extent to which a data point deviates from the norm.
- Interquartile Range (IQR): IQR defines the range of typical values and helps identify outliers beyond the upper or lower quartile boundaries. This technique is robust to extreme values and provides a non-parametric approach to outlier detection.
- Boxplots: These visualizations represent the distribution of data, with outliers appearing as data points outside the box whiskers. Boxplots offer a quick and intuitive way to identify outliers and understand the overall distribution of the dataset.
- Scatterplots: Scatterplots can reveal unusual patterns or clusters that might indicate outliers, especially in multivariate analysis. By plotting different variables against each other, scatterplots help in identifying data points that deviate from the expected relationships or trends.
Contextual Anomalies
Contextual anomalies refer to data that is inconsistent within a specific context. These anomalies can manifest in various forms:
- 1. Logical inconsistencies: For example, an order placed before the customer created an account. Such anomalies violate the expected logical flow or sequence of events and can indicate issues with data integrity or system processes.
- 2. Referential integrity issues: An example is a product ID in an order that doesn’t exist in the product database. These anomalies arise when there are discrepancies between related data entities and can lead to errors in data processing or reporting.
- 3. Missing or incomplete data: One case is a customer record with no address information. Incomplete or missing data can hinder analysis and decision-making, as it may not provide a comprehensive view of the entity or transaction.
To identify contextual anomalies, organizations can employ the following approaches:
- Data validation rules: Defining acceptable ranges or formats for data entry can help catch contextual anomalies during the data entry process. By establishing validation rules based on business requirements and data quality standards, organizations can prevent the introduction of anomalous data at the source.
- Defining expected relationships between data points: Understanding the relationships between data points (e.g., order quantity and product price) can help identify anomalies where those relationships are violated. By modeling these relationships and setting thresholds for acceptable deviations, organizations can detect contextual anomalies that do not align with expected patterns.
Collective Anomalies
Collective anomalies refer to groups of related data points that exhibit unusual behavior when considered together. Examples of collective anomalies include:
- 1. Sudden spikes or dips in time series data, such as sales figures or website traffic. These anomalies may indicate significant events, system failures, or changes in user behavior that require further investigation.
- 2. Correlated fluctuations in unrelated metrics, like an increase in server load coinciding with a surge in user login attempts. Collective anomalies can reveal hidden relationships or dependencies between seemingly unrelated variables, providing valuable insights into system performance or security threats.
Identifying collective anomalies often involves:
- Real time anomaly detection algorithms: These algorithms learn historical data patterns and flag deviations as potential anomalies. By training machine learning models on large datasets, organizations can use automated systems to detect collective anomalies that may be difficult to identify through manual analysis.
- Time series analysis: Analyzing trends and seasonality in time series data can help identify unexpected changes or disruptions. Techniques such as moving averages, exponential smoothing, and anomaly detection models can be applied to time series data to uncover collective anomalies and assess their impact on business operations.
Effectively Investigating the Source of the Anomaly
To effectively identify data anomalies, it is crucial to have a comprehensive understanding of your dataset. Familiarity with typical ranges, trends, and patterns within the data enables you to recognize anomalies more easily. This understanding also helps in distinguishing anomalies from expected variations, such as seasonal fluctuations or normal data distribution.
Developing a deep understanding of your data requires collaboration between domain experts and data professionals. Domain experts, such as business analysts or subject matter experts, possess valuable insights into the business context and can provide guidance on what constitutes normal behavior or expected patterns within the data. Data professionals, including data scientists and data engineers, bring technical expertise in data analysis, statistical techniques, and machine learning algorithms. By fostering a collaborative approach, organizations can leverage the combined knowledge and skills of these teams to identify anomalies effectively.
Leveraging Data Visualization Tools
Data visualization tools play a significant role in facilitating anomaly detection. By providing intuitive visual representations of the dataset, these tools help in identifying outliers, patterns, and relationships that may indicate anomalies. Scatter plots, boxplots, histograms, and other visualization techniques can highlight unusual data points or abnormal behavior. Interactive dashboards and data exploration platforms enable users to drill down into specific data subsets, compare different variables, and uncover hidden insights.
When selecting data visualization tools, organizations should consider factors such as ease of use, flexibility, and integration with existing data infrastructure. The chosen tools should support a wide range of visualization options and allow for customization based on specific business requirements. Additionally, the ability to share and collaborate on visualizations across teams can foster a data-driven culture and improve the efficiency of anomaly detection processes.
Data Quality Checks
Setting up data quality checks and alerts is another proactive measure for system health monitoring and maintaining data quality. By establishing automated checks and alerts, organizations can promptly flag anomalies or deviations from expected patterns. These checks can be implemented at various stages of the data pipeline, from data ingestion to data transformation and analysis. Real-time notifications enable stakeholders to detect anomalies promptly, minimizing the impact of data quality issues.
Data quality checks can include validation rules, integrity constraints, and statistical thresholds. One common setup is range checks for numerical values, enforcing referential integrity between related data entities, or monitoring for sudden spikes or dips in key metrics. Automated alerts can be triggered based on predefined conditions or anomaly detection algorithms, notifying relevant teams or individuals via email, SMS, or other communication channels.
Dealing with Data Anomalies
When data anomalies are identified, it is essential to investigate their underlying causes thoroughly. This investigation involves exploring potential sources of anomalies, such as data entry errors, system malfunctions, or genuine outliers resulting from unique events or circumstances. Conducting root cause analysis helps pinpoint the specific factors contributing to each anomaly, enabling appropriate corrective actions.
Root cause analysis involves a systematic approach to identifying the fundamental reasons behind data anomalies. It requires collaboration between data professionals, domain experts, and IT teams to gather relevant information, analyze data lineage, and review system logs or processing workflows. By asking probing questions, such as “What changed in the data collection process?” or “Are there any correlations with other system events?”, organizations can uncover the root causes of anomalies and develop targeted solutions.
Data cleaning techniques play a crucial role in rectifying anomalies and improving data quality. These techniques include methods for correcting errors in the dataset, such as data imputation, interpolation, or deletion of erroneous entries. Data imputation involves filling in missing or incorrect values based on statistical models or domain knowledge. Interpolation techniques estimate missing values by leveraging the relationships between adjacent data points. In some cases, deleting erroneous entries may be necessary to maintain the integrity of the dataset.
When dealing with outliers, it is important to distinguish between genuine anomalies and valid data points, considering their impact on the analysis and the underlying data distribution. Outliers that are the result of data entry errors or system malfunctions should be corrected or removed to ensure the accuracy of the entire dataset. However, genuine outliers that represent rare but valid occurrences may provide valuable insights and should be retained for further analysis.
Establishing documented procedures and protocols for handling data anomalies within an organization is vital for consistency, accountability, and transparency. These procedures should outline anomaly detection thresholds, escalation protocols, and resolution workflows. They should define roles and responsibilities, specifying who is responsible for identifying anomalies, investigating their causes, and implementing corrective actions.
Regular review and refinement of these procedures ensure adaptability to evolving data sources, technologies, and business requirements. As new data sources are integrated, new anomaly detection techniques are developed, or business priorities change, the procedures should be updated accordingly. Continuous improvement and learning from past anomalies can help organizations enhance their data quality practices and build resilience against future data quality issues.
Conclusion
Data anomaly fault detection plays a critical role in ensuring the integrity, reliability, and usefulness of datasets. By identifying and addressing data quality issues, organizations can reap the benefits of working with clean, high-quality data. Clean data enhances the reliability and credibility of analytical results, leading to more confident decision-making and strategic planning.
The impact of data quality extends beyond individual business units or departments. It affects the entire organization, from operational efficiency to customer satisfaction. Inaccurate or inconsistent data can lead to suboptimal resource allocation, missed opportunities, or even reputational damage. On the other hand, high-quality data empowers organizations to make data-driven decisions, optimize processes, and deliver exceptional customer experiences.
It is important to recognize that data quality is an ongoing process rather than a one-time task. Continuous monitoring, maintenance, and improvement efforts are essential to maintain the accuracy and consistency of datasets. By investing in effective anomaly detection techniques, documenting procedures, and fostering a data-driven culture, organizations can harness the full potential of their datasets and make informed decisions with confidence. Tools like Anomalo can assist organizations in implementing continuous data quality monitoring, automating anomaly detection, and streamlining the resolution process.
Anomalo provides a comprehensive platform for data quality management, leveraging machine learning algorithms and advanced anomaly detection techniques. It integrates seamlessly with existing data infrastructure, enabling real-time monitoring and alerting of data anomalies. By automating the identification and classification of anomalies, Anomalo helps organizations save time and resources while ensuring the highest levels of data quality.
Take the first step towards ensuring data quality by exploring the capabilities of Anomalo’s data quality software and requesting a demo today.
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Ready to Trust Your Data? Let’s Get Started
Meet with our team to see how Anomalo transforms data quality from a challenge into a competitive edge.