Data Modernization with Databricks and Anomalo
March 7, 2024
![]()
Data modernization is something businesses talk about frequently. But what does that really mean from a practical perspective? What should you be considering as you plan a modernization strategy, and what are some components that will help your business manage a hybrid multi-cloud environment more effectively?
Recently, Databricks and Anomalo were invited to participate in a webinar hosted by TDWI, an industry leader in research and education for data management, analytics, and AI. This webinar covered:
- Cloud modernization, specifically of the data environment
- How modern approaches to data quality are superior to historical ones
- The challenges of maintaining cloud data quality
- How Databricks + Anomalo help address these challenges
In this blog post, we’ve summarized the highlights.
What cloud modernization means for the data environment
“The cloud environment fundamentally changes the way that organizations make use of information,” said David Loshin, TWDI expert and senior lecturer at the University of Maryland. Organizations can better formulate their reporting and analytics capabilities and address an expanding array of different types and classes of data consumers.
Benefits of the cloud include:
- Cloud resources can be configured on demand.
- Cloud processing allows for a lot more flexibility. When you consider the capabilities of different cloud service providers, you can use, combine, and integrate data in new ways for a wide range of different business opportunities.
- Cloud computing is scalable. Cloud configurations allow you to bridge across an increasingly distributed landscape of data resources, supporting both data that remains on premises and data that’s sitting in cloud object storage, cloud data warehouses, and/or lakehouses.
- Cloud workloads can make use of automation. This eliminates the need for an individual to be sitting with a finger on the pulse of a specific data application and massively increases the opportunities for what a business can do with data.
The traditional approach to data quality is insufficient in a cloud environment
“Everything in terms of data use is also dependent on data quality,” Loshin said. However, data quality is typically introduced at the wrong point in the data lifecycle.
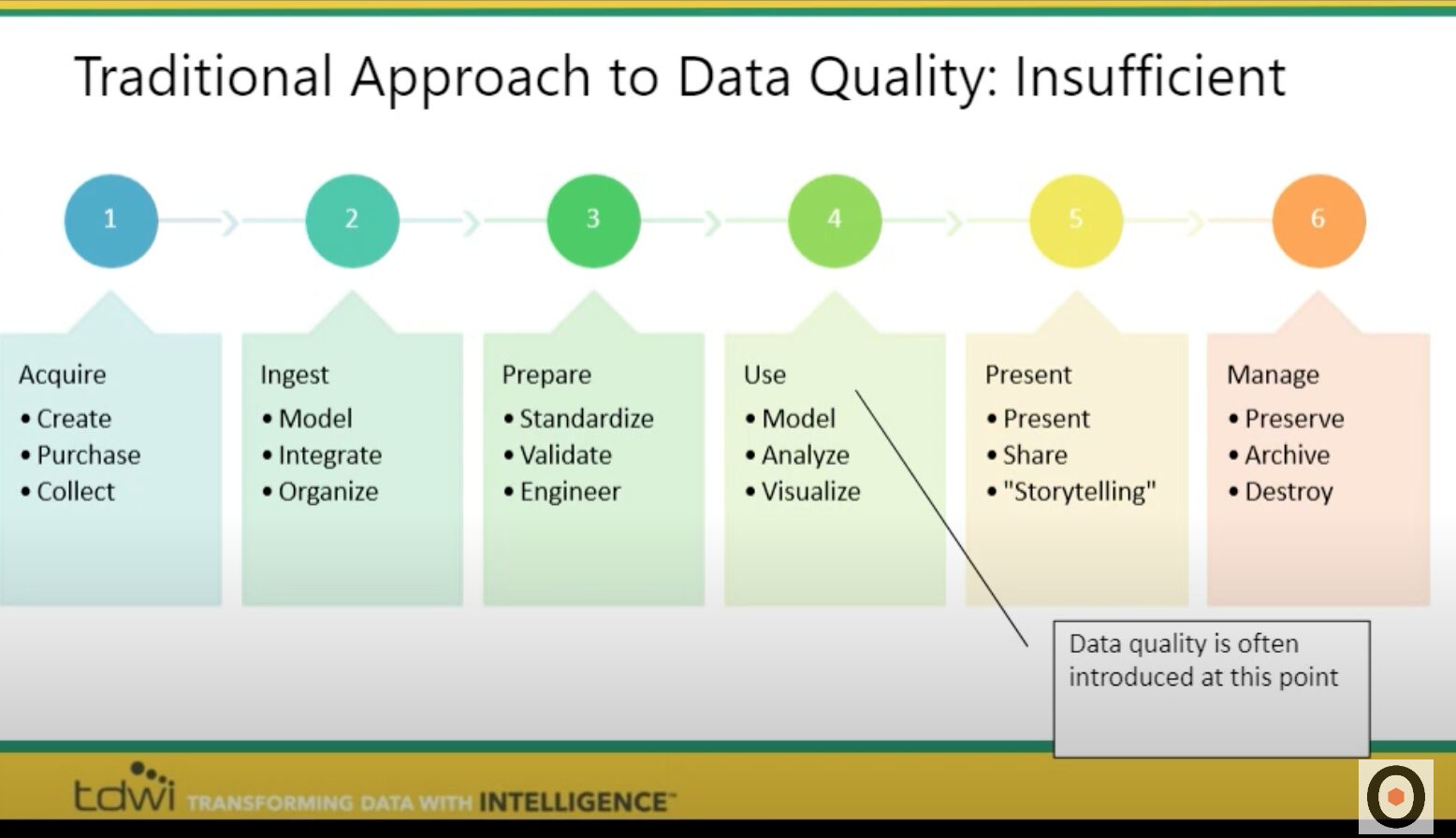
Data quality is often being introduced between stages three and four, either when data is prepared (standardized) prior to use, or right before data is subjected to reporting, analysis, or modeling.
“The traditional approach to data quality, which focuses solely on cleansing data at one particular point, is insufficient to meet the needs of an expanding multi-cloud hybrid environment,” Loshin said. Data quality needs to be addressed across all phases of the analytics lifecycle — from the acquisition point of the data, all the way through to managing or archiving data after use.
The challenges of managing cloud data quality
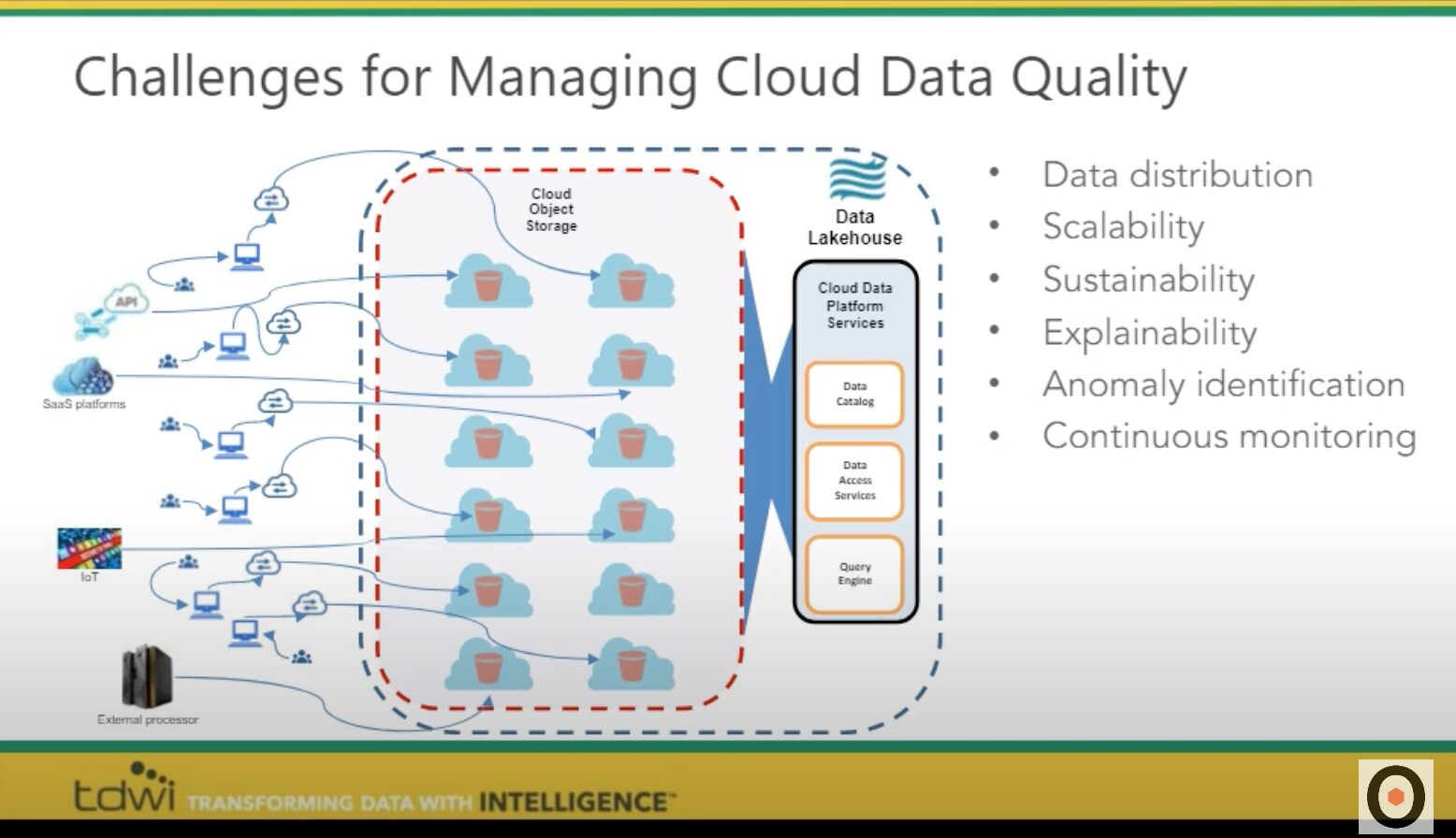
A cloud data environment generally works in the following ways:
- Data is moved from different sources into some kind of cloud object store. A modern lakehouse architecture will then enable comprehensive data services on top of the store.
- Data consumers use a data catalog or other form of accessibility to understand these different resources
- A query engine provides the ability to take a request for data and translate that into its component pieces, providing a result set that hides the complexity of the different architectures from the data consumers
Together, these aspects make the data cloud a vast improvement over the way data has been managed for the past three decades. Data stores and consumers are no longer forced to use strict data models in structured data warehouses before processing and using data at scale.
But there are some challenges associated with managing data quality in this environment. The distributed architecture is complex, making it difficult to ensure that all consumers can trust and verify the result sets that come through. In addition, you must ensure that the computing and performance scales to a growing number of data consumers.
Modernizing your data environment with Databricks
One aspect of modernization that many companies struggle with is managing all the different components of their data platform. If you’re on AWS, that might look like a mix of S3 and Redshift along with Airflow for orchestration, SageMaker for data science, and a streaming data component with Kinesis — to name a few. It’s hard to provide consistent policies across these components and very complex to stitch them together.
“The data lakehouse is a different approach,” explained Denis Debeau, Partner Solution Architect at Databricks. “It starts with your cloud data lake. You have one platform to manage all your types of data. You have one security model, one governance capability, and you also address all the different personas of your enterprise from — from your data warehousing and BI, to your data engineering and DevOps, to your data streaming and data science.”
Databricks relies on technologies like the Delta Lake file format to unify data warehouses and lakehouses, and Unity Catalog for governing all data assets and components. Functionality for different consumers includes Databricks SQL, Databricks Workflows, Delta Lake Table for streaming, and MLFlow for machine learning applications.
Through the Databricks Partner Connect program, additional applications in the data ecosystem can be fully integrated across the entire lakehouse. Anomalo was one of the first partners in Partner Connect, providing data quality monitoring for the Databricks lakehouse.
Modernizing your data quality with Anomalo
Anomalo is an AI-powered data quality monitoring platform that can automatically detect anomalies in your data and find the root cause.
This is especially important as companies increasingly rely on their cloud data stack to drive business objectives. “Lakehouses like Databricks are the source of truth for analysts who ultimately make decisions for the business. And the only thing worse than making decisions on no data would be making decisions on bad or wrong data,” explained Zach Wright, data analyst and engineer at Anomalo.
Anomalo allows you to monitor data in a scalable way with three categories of checks:
- Validation rules that provide granular, record-level checks for your key tables
- Metric anomalies, such as high-level changes KPIs that business leaders are tracking
- Unsupervised data monitoring, which is a very new way of monitoring the data quality in the lakehouse. This takes a sample of today’s data and determines if it’s drifted in any significant way compared to historical data. It’s completely automated and doesn’t require any configuration.
This leads to a more scalable paradigm for data quality. Instead of the typical approach of starting with rules, leaders can start with a foundation of global, unsupervised data monitoring to detect significant shifts in the data and even find “unknown unknown” issues. Then, for the tables and columns that are really important, they can add validation rules and metric anomalies.
Additional features of Anomalo include:
- Automatically generating a root cause analysis as soon as an anomaly is detected
- False positive suppression to reduce noisy alerts
Watch the full webinar below:
From modernization to activation: Where do we go from here?
For Databricks, the lakehouse was just the starting point. The Databricks Data Intelligence Platform merges the lakehouse architecture with Generative AI, enhancing the implementation of data science applications across enterprises. This will shift the focus even more towards data quality.
As Databricks customers increasingly rely on their data for automated insights and customer experiences, data quality will be a baseline necessity. Importantly, data quality issues are one of the largest, if not the largest, blockers enterprises face in maximizing the value of data and AI (Source). Data anomalies can slip through the cracks, and organizations can struggle to scale their data usage while maintaining trust in the data.
Databricks and Anomalo work together to address these challenges, with Databricks reducing the complexity of managing many different components across the data stack, and Anomalo ensuring that none of these components suffer from quality issues at any point in the data lifecycle. Anomalo integrates with Databricks through the Partner Connect program. You can start there, or request a demo of Anomalo from our team.
Categories
- Integrations
- Partners
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Ready to Trust Your Data? Let’s Get Started
Meet with our team to see how Anomalo transforms data quality from a challenge into a competitive edge.