Control Your Own Data with In-VPC Deployment
March 28, 2023
It doesn’t matter how compelling a software vendor’s offerings are if your cybersecurity team says no. Enterprises are rightfully concerned with data privacy, security, and the risk of data leaks, especially as they relate to testing new software products. With strict regulations around data compliance and the ever-present threat of bad actors, businesses need to be extremely careful about who has access to their data.
Consequently, we’re seeing a shift in how vendors position their data tools. Instead of centrally hosted software as a service (SaaS), customers are opting for deployments inside their virtual private cloud (in-VPC) that they can control directly. Rather than being a binary, SaaS and in-VPC deployments sit on a spectrum, with some providers selling hybrid solutions. In this article, we’ll examine the tradeoffs around each model and make the case that true in-VPC deployments are the only guaranteed way to maintain complete ownership over your data’s security.
The three categories of data companies need to manage
To set the stage, it helps to enumerate the three main types of enterprise data:
- Row-level data: The individual records in your data tables. This is the most granular form of data and can include personally identifiable information (PII).
- Key business metrics: These are aggregations that can still be very sensitive to keep private. Examples include sales order counts and financial summaries.
- Metadata: This includes any information that describes the rest of your data—for instance, all the column names in your ML feature store.
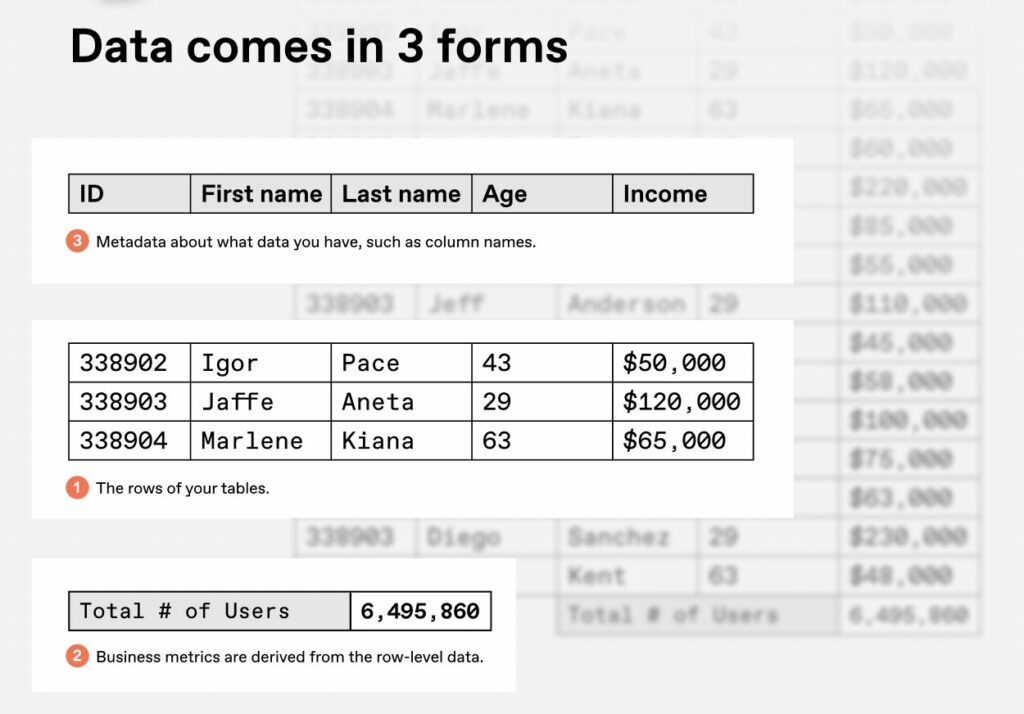
Typically, businesses care most about protecting their row-level data, especially because of the PII it might contain, followed by key business metrics as the next priority. Of course, companies prefer to secure all their data including metadata, since even leaking your tables’ column names could give a major advantage to competitors.
As a customer, you should understand what a vendor means when they say they’ll store data in your own cloud. These claims can sometimes be misleading if they implicitly describe only some types of data. Some solutions keep all three types of data under either the vendor’s or the customer’s control, whereas other approaches split how data gets stored. Distinguishing between these categories of data gives us a framework to evaluate software deployment models.
SaaS is the simplest model but adds complexity for data security
The SaaS licensing model is very straightforward. The vendor takes care of running their software and to facilitate this, your data lives in the vendor’s cloud. With SaaS, you can start using the vendor’s product with little to no setup, and you don’t have to worry about product updates either, since the vendor manages that. You know exactly what you’re getting and can expect the vendor to deliver that each month or year you pay a recurring fee. Many familiar services are SaaS products, including QuickBooks, Google Workspace, and Salesforce.
The biggest drawback of SaaS is that you have to sacrifice control for convenience. It takes a lot of trust to navigate to a website, input your data warehouse credentials, and let a third party service run queries against your data. The prospect of hosting business data in a vendor’s environment will be a non-starter for the most stringent enterprise security teams, whether by choice or because of regulation.
Any worthwhile SaaS offering should encrypt your data to keep it safe, and for the most part, plenty of companies have subscribed to SaaS products without issue. That said, SaaS providers periodically make headlines when they experience data breaches and cloud leaks. While there are never guarantees in the field of data security, storing your data in fewer places is one way to reduce risk.
Hybrid deployments are an awkward middle ground
Any deployment that isn’t strictly SaaS or fully in your virtual private cloud could be called a hybrid. As such, there is a whole range of hybrid solutions that vary in how they partition data between the vendor and customer’s clouds. Generally speaking, hybrid software includes an interface layer between the two clouds and delineates functionalities such that the vendor owns the business logic and the customer retains most of their data, at least in name.
The hybrid model promises the best of both worlds, in that it’s theoretically low-effort to configure and maintain, while offering heightened data security standards over SaaS. In practice, hybrid deployments rarely live up to these expectations. With respect to data security, hybrid isn’t always that different from SaaS. Some hybrid implementations use a data collector that emits data from your cloud to the vendor’s for further processing, exposing your data to some of the same risks of SaaS.
It can be tricky to trace the flow of data in a hybrid application, especially if a vendor isn’t upfront about their software architecture. Worse yet, some vendors market their product as completely in-VPC, when that’s only partially true. Look out for vendors requesting that you grant access to specific IP addresses; this is a red flag that their offering is a hybrid solution, not on premises.
Also look out for signs of what data a hybrid application is consuming. The vendor probably needs access to metadata at a minimum, and depending on the specific architecture, other data may be flowing between the two clouds. You might assume that your row-level data isn’t being touched, but if the vendor’s application is running analyses that wouldn’t be possible without that data, then think again about what’s truly secure. Most of the time, hybrid deployments are more hassle than SaaS without meaningfully improving data security.
Virtual private clouds are the only way to retain full data ownership
With an in-VPC deployment, all of the vendor’s business logic and data management happens in the customer’s cloud. This approach is similar to how you might self-host open source software. With in-VPC, you can be absolutely sure your data stays with you, which your security and compliance teams will be happy to know. On the other hand, customers have sometimes shied away from using self-managed software because it’s more burdensome to configure and update than SaaS.
Nowadays, some vendors are investing into making their in-VPC deployments very user friendly. With the modernization of software architecture including technologies such as containerization, deploying new software is simpler than ever.
All of this is certainly more effort on the vendor’s part, which is why only a handful of software products make it easy to run in your own cloud. Indeed, vendors that cut corners will try to pass off their hybrid solutions as in-VPC precisely because it’s so time intensive to implement a full self-managed solution.
Anomalo offers fully in-VPC data quality monitoring in addition to SaaS
At Anomalo, we’re proud to offer our ML-powered data quality software in both a SaaS model and as an in-VPC solution. We let you decide which approach best suits your needs, and we’ll work directly with you to get either deployment type running as soon as possible. If you want to monitor all your data, you can’t expect a hybrid solution would avoid transmitting that data. That’s why when it comes to data quality monitoring, we believe in committing to SaaS or in-VPC. We’ve dedicated extra attention to creating a best-in-class in-VPC deployment that removes a lot of the confusion and frustration self-managed software usually entails.
To learn more, request a demo of Anomalo today and learn how Anomalo keeps customer data truly secure.
Categories
- Product Updates
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Ready to Trust Your Data? Let’s Get Started
Meet with our team to see how Anomalo transforms data quality from a challenge into a competitive edge.