Pair Anomalo with Databricks for Accurate Financial Risk Management
April 29, 2024

Financial services institutions (FSIs) make money by taking smart risks. They save money by minimizing avoidable ones.
The only way to systematically reduce risk is by properly understanding where the risk is and how much of an impact it could have. Modern FSIs do this with risk modeling, with entire risk management teams staffed with analysts and managers. The stakes are high: not only do execs and shareholders want to avoid losing money, but regulators also directly scrutinize FSIs’ analysis of their own risk exposure to ensure market stability. (Risk management as a field has grown in attention since the 2008 global financial crisis.)
Some of the questions important risk management models answer include:
- Value at Risk (VaR): How much money would it be reasonable to expect to lose in a given timespan?
- Liquidity Risk: Can enough assets be made liquid quickly enough to cover obligations?
- Credit Risk: How likely is it that loans won’t be repaid?
Risk mitigation at FSIs has become more sophisticated and data-driven, and in general, faster and more accurate. Alongside an explosion in available data and computing power, FSIs can use very powerful cloud-based tools to manage and manipulate data. A core practice is applying machine learning (ML) models to predict credit risk, detect fraudulent activities, and anticipate market changes more effectively. Real-time data allows for even more dynamic risk assessment, enabling FSIs to adjust their strategies quickly in response to changing market conditions.
Yet, as FSIs have embraced and automated decisions with vast volumes of data, they have unwittingly created a new form of risk. Bad or missing data could mean approving the wrong loan, declining a valid transaction, or prematurely selling a promising security. Most perniciously, if ML models train on bad data, they could deliver poor outcomes even when given accurate inputs for a particular decision.
This isn’t to say you should revert to handshakes and hunches for risk decisions. You simply need a modern solution to a modern challenge. Anomalo reduces the risk of bad data, making your analysis with Databricks all the more reliable.
Why FSIs use Databricks for risk management
Databricks Data Intelligence Platform, leveraged by some of the largest FSIs in the world, is a fantastic platform for both organizing enormous amounts of data from various sources and running AI/ML models on top of it. In fact, over 1,000 FSIs, from HSBC to Block (Square’s parent company), use Databricks to store the data and power the models that support important parts of their business, including risk management. Data Intelligence Platform, built on lakehouse architecture, enables the ideal combination of data scale and performance, and Unity Catalog simplifies both the architecture and governance of vast amounts of data. In other words, Databricks can not only handle data at the scale of the largest FSIs but also make it a lot easier to keep track of, interact with, and learn from.
Let’s look at how they help with Value at Risk (VaR), starting with a quick summary of this model type. It’s a way of assessing the downside of an investment. You start with a timeframe—days, weeks, or longer—and percentage confidence, typically 95% or 99%. So, a VaR calculation aims to answer a question like, “Over the next two weeks, 95 times out of 100, how much money might I lose?” (VaR excludes the worst cases to give a meaningful floor.)
There are many equations out there for calculating VaR. Inputs could include historical stock performance, market volatility, news analytics, or other data relevant to the risk you’re assessing. Over the past decades, FSIs have invested in expensive on-premise systems to store and process this data into models. Even though this is a big upgrade from pen and paper, processing and storage capacity limitations constrain the number of variables as well as how much you can infer from their interaction. Then, when it comes time to run the model, you’re limited by the data you have on hand and whenever it was last refreshed.
Databricks solves those challenges by making it easy for FSIs to store and govern vast amounts of data and run dynamic VaR models on top of it. There are many good reasons to upgrade to cloud-based VaR built on ML and a wide range of data sources. Let’s name three:
- More variables. If you can account for more factors simultaneously, your calculations can be more calibrated to the particular circumstance. This includes historical data that train the model and the inputs to evaluate.
- Fresher data. Not only does Databricks allow you to store and manage a lot more data, but it also helps you keep it up to date. For instance, you can make decisions based on the latest stock quote, not yesterday’s closing price.
- Better model training. ML can make connections between and inferences upon data far beyond humans’ capacity. Scalable cloud computing can do a lot more calculations, much faster and cheaper than on-prem. The result is a much better model and simulations in the millions, not just thousands.
There’s one more reason why Databricks specifically is an excellent choice for FSIs. Beyond the incredible infrastructure, they offer practical tools for FSIs to use. Their proven Solution Accelerators, such as Modernizing Risk Management, reduce the time, cost—and risk—of starting VaR calculations from scratch. It comes with a thorough walkthrough and the exact code you’ll need. Because Databricks has taken care of everything from instruction to troubleshooting, you can start using much more powerful models sooner, but the model itself is de-risked because of the thorough testing it’s been through.
Now, let’s talk about data quality.
Bad data: what it is and why it’s harmful
Risk models are intended to reduce risk. Running risk models on bad data actually increases it.
Bad data can end up in your data platform in several ways, from false inputs (typos, lies, faulty sensors) to table format (invalid dates, wrong postal code format) to the pipeline (mislabeling, corruption, truncation). Whether deleted, repeated, or mistreated, data that does not accurately reflect reality will misinform your risk models and lead to suboptimal outputs.
There are three major ways that bad data can manifest in FSIs’ risk practices. Let’s look at it in the context of generating an auto insurance quote.
- Evaluating risk on the right data. You need accurate inputs to make the smartest decision. This data comes from many different sources—zero-party from the customer (such as driver’s age, car make and model, zip code), first-party from your internal sources (payment and claims history), and third-party from other sources (credit score, crime by zip code). If any of those are inaccurate, you will likely end up underquoting (thus not sufficiently capturing the risk of claims) or overquoting (and losing the customer to a better-priced competitor).
- Training your models correctly. Just as you need accurate data as input for a decision, you also need it for the model to reflect the state of the world correctly. In the old days, a discerning analyst might find discrepancies or data misalignment when manually constructing a model. AI generally lacks such discernment and takes all its data at face value. When training data is bad, many or even all of the model’s outputs could create risk rather than reduce it.
- Satisfying regulators. ML-based models are much more complex than traditional equation-based approaches. They’re often opaque, too, meaning they don’t say how they arrive at their conclusions. This makes the quality and reliability of the input—factors that can be audited and verified—much more important to people charged with ensuring that your financial processes are sound and fair. Then, once you’ve run the models, you must make what you deliver mistake-free to regulators. If they are displeased with your processes to ensure you’re basing models on good data, or find bad data in your inputs or outputs, you risk regulatory action around the very process intended to mitigate risk.
Traditional data quality monitoring is unfit for the task
Data quality is not a new concept. For decades, data engineers have worked with their business counterparts to develop validation rules to make sure that a modest number of tables are as they ought to be: values in all required columns, US phone numbers ten digits long, parents older than their children, updates recorded on a predefined schedule.
This approach can’t keep up with the explosion in the amount of data FSIs use—orders of magnitude more tables, data updated much more frequently, and entire datasets added, removed, and adjusted all the time. There are three major reasons:
- Hard coding doesn’t scale. You can’t hire enough data engineers to write all the rules you’d need to monitor petabytes of data across thousands of tables.
- You can’t anticipate everything. So many things can go wrong, especially when incorporating third-party data whose provenance and pipeline are out of your control.
- ML amplifies errors. Inaccurate inputs in a calculation affect one decision. Bad training data leads to a machine learning model spitting out suboptimal results for every decision, if not causing the model to fail entirely. When the impact is from plausible but simply wrong data, it’s difficult, if not impossible, to observe the impact, let alone diagnose the source.
One example, based on a true story, comes from a bank that tried to improve its liquidity risk management with a model to predict its commercial lending customers’ deposit behavior. They used a time-series dataset and industry classification codes to train the model on the patterns exhibited by different types of businesses.
But what if the industry classification criteria were to change and certain businesses recategorized? A data quality rule that’s only set to detect invalid codes wouldn’t trip. The model wouldn’t be able to match pre- and post-change points in the time series for these assets, and the bank would then be basing its liquidity management on a now-outdated model.
In other words, feeding modern scales of data into machine-learning models without equally up-to-date data monitoring could cost you millions.
Databricks is transforming the way FSIs use ML and AI to power their business. Data quality is a critical first step, and the scale and wide range of source inputs makes it increasingly difficult to do well using deterministic approaches. But that’s the beauty of Anomalo’s unsupervised machine learning. It can learn the patterns of any financial data set and quickly identify erroneous data.
– Antoine Amend, Sr Technical Director – Financial services
Smoke detectors in the Lakehouse: Anomalo for comprehensive data monitoring
A smoke detector detects and alerts when something unusual is happening. Within seconds, you can figure out which room the sound is coming from and address the issue before it gets out of control.
Anomalo works in much the same way, albeit without the deafening tones. It goes a step further by pointing you to exactly where the fire is coming from. As the name suggests, it looks for anomalies: patterns in your data that are notably different from normal. Root cause analysis can help you narrow down where to look for the issue. And it can be used across all your data. When coupled with Unity Catalog and its built-in lineage, it also helps you understand the downstream impact of erroneous data.
“Anomalo has been the silver bullet in helping us promote trust in data across our organization,” said Tim Ng, Data Products Engineering Lead at Block. “Since migrating to Anomalo, it is easy to detect false positives and has removed dependencies on data engineering. This makes both my data engineers and data consumers happy as it means less time fire-fighting issues, and more time using data to build products our customers love.”
Anomalo can be incorporated within your Databricks pipelines to monitor data in flight, configured on a specific layer of the medallion architecture (e.g., bronze, silver, gold), or all the above. This allows data teams to learn about and resolve issues before they surface in risk models. If VaR or other risk calculations are like recipes, think of Anomalo as letting you know if any ingredients are missing or expired before you start cooking.
Reference architecture:
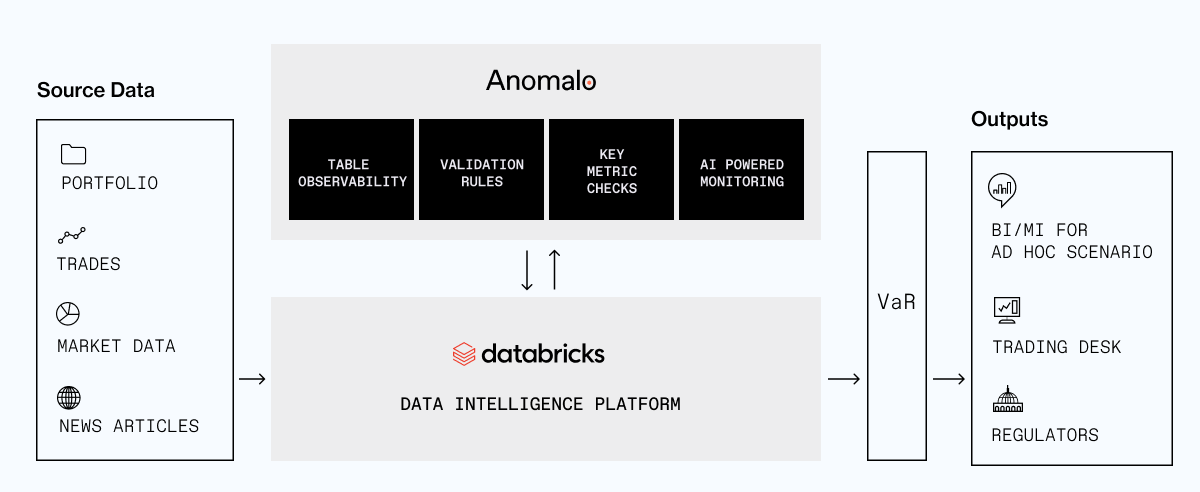
Unsupervised machine learning is the key. Anomalo observes your datasets over time and, within a few months, becomes keenly attuned to factors like frequency and pattern of changes, typical distribution of values in any column, and even relationships between the values in different columns. If something suddenly looks off, it’ll notice and notify. (There’s still a place for rules, particularly to point ML in particular directions that you know are important to get right, as well as to save on compute usage for straightforward checks.)
In other words, unsupervised machine learning goes beyond metadata and observability checks, inspecting the contents of the data itself. With the industry classification example above, Anomalo would have observed that the behavior of assets with certain category codes had suddenly changed. The range of values and presence of industry classifications would have appeared normal to a standard hard-coded check, but Anomalo would pick up on a suddenly changed pattern.

Anomalo can automatically detect distribution shifts or unexpected increases in anomalous values within segments.
Anomalo’s unsupervised machine learning is also particularly useful for monitoring third-party data, such as from the Databricks Marketplace. A provider’s error isn’t your responsibility, but it becomes your problem when you rely on it to train models or make risk decisions. Even if you know little about where the data comes from or what’s likely to go wrong, Anomalo’s got you covered.
In fact, Anomalo is deeply integrated with Databricks, bringing several benefits:
- Simple setup: Connect Anomalo to Databricks and quickly set up automated monitoring on any given table or view. A native integration with Unity Catalog (UC) allows customers to run hourly observability checks across their entire Databricks platform efficiently.
- Impact analysis: Anomalo pulls lineage data from UC to help customers understand the impact of data quality issues and how to fix them.
- Embedded trust signals: Because Anomalo pushes check results directly into UC’s Data Explorer UI, many data users won’t ever have to log into Anomalo’s platform to benefit from its reports.
- Unified access: For those who will be setting up checks or analyzing anomalies, Anomalo can parallel UC’s access groups for consistency.
Anomalo is available via Databricks Partner Connect, offering Databricks customers an exclusive and convenient free trial of the Anomalo platform. Since it’s simple to set up and straightforward to learn, you can see firsthand how Anomalo would work with the data you already use on AWS, Azure, or GCP.
Data presents enormous opportunities for FSIs to optimize decisions, operations, and profit, and many are drawn to Databricks to manage and manipulate data at huge scale. But risk is everywhere in financial data, and if you’re using more data than before, that’s more risk. Fortunately, Anomalo is proven, cost-effective, and straightforward to implement: a low-risk way to lower your risk.
Categories
- Industry - Financial Services
- Integrations
- Partners
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Ready to Trust Your Data? Let’s Get Started
Meet with our team to see how Anomalo transforms data quality from a challenge into a competitive edge.