Discover’s Approach to Scaling Enterprise Data Quality Monitoring
October 17, 2023
You may have never needed to know the metric prefix zetta, which is of a scale a trillion times bigger than giga. You will be glad you know now, because by the year 2025 the volume of data created, captured, and consumed worldwide is projected to grow to more than 180 zettabytes.
The financial services industry will inevitably have to deal with this data explosion. Compounding this data explosion problem is the advent of Generative Artificial Intelligence (Gen AI) which is making data in unstructured formats more accessible and faster to get to than ever before. More data should be good for generating better insights, right? Well, only if that data is of high quality. Garbage In, Garbage Out! In financial services, we have a responsibility to ensure that data is of high quality, and timely, so that the data-driven decisions we make do not result in customer harm.
In this case study, I’ll share my experiences in the role of Senior Director of Enterprise Data Platforms at Discover Financial Services (Discover), where we have a large suite of products in digital banking and payment services being supported by hundreds of software applications that produce and persist petabytes of data. With that much data, there are countless ways data integrity could be compromised, particularly when the data flows from operational systems to analytical systems for reporting, decisioning, and advanced analytics. At Discover, we have had to think deeply about how to define high data quality, how to reach that bar, and how to continue to monitor data quality over time and at scale. By the end of this case study, you will understand the fundamental challenges with traditional, deterministic data quality monitoring and why Discover found success subscribing to an automated data quality software designed with big data in mind.
What makes data high quality?
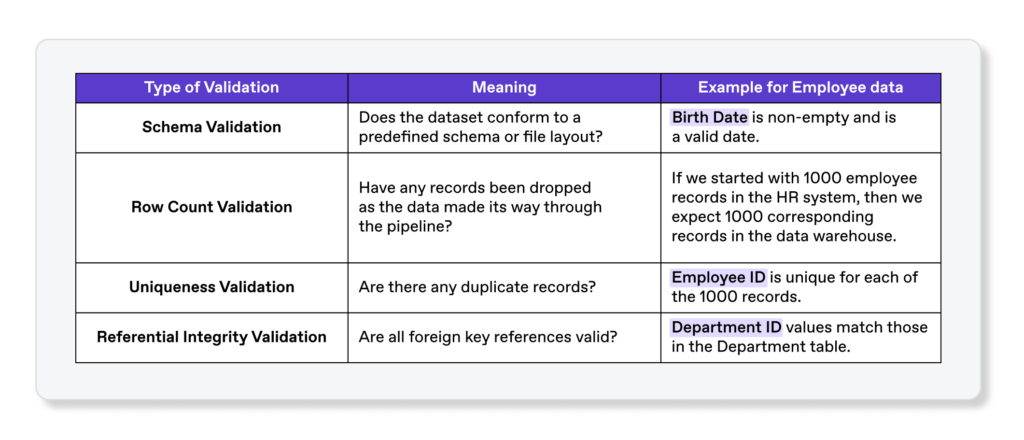
While aspiring data experts should read about the many dimensions of Data Quality (DQ), in this case study we will use a simpler model as a starting point. The Completeness, Accuracy, and Timeliness (CAT) controls model describes data as high quality if it meets the following criteria:
- Complete: The data is comprehensive and not missing information
- Accurate: The information contained in the data is a correct representation of the real world
- Timely: The data is made available quickly enough to be useful
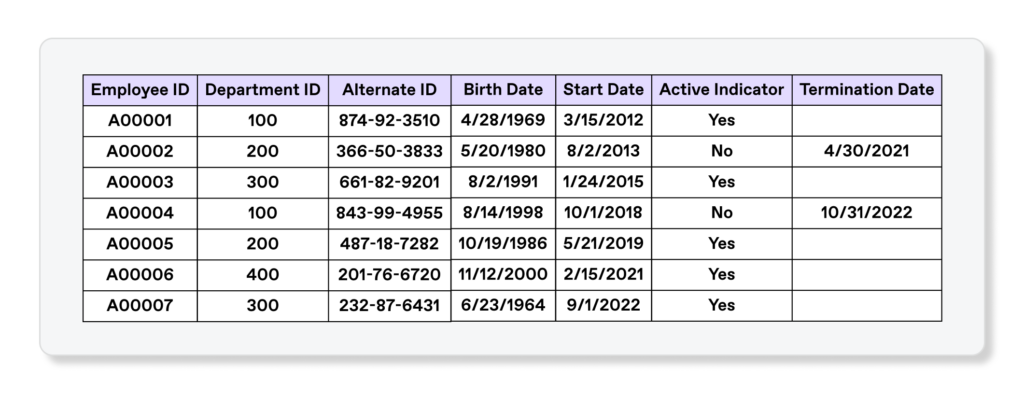
At Discover, we have a series of CAT controls to ensure that data quality meets our corporate risk appetite. We group these controls into two broad themes that tackle technical data quality and business data quality, respectively. To highlight the distinction between these themes, let’s consider the hypothetical scenario of loading an employee dataset from a HR system into a data warehouse.
Technical Data Quality
Technical data quality encompasses the fundamentals of a company’s data and accompanying infrastructure. Data pipelines should be operating smoothly, data should be easily accessible, and the data itself needs to be valid at a foundational level. In the case of the hypothetical employee dataset, some checks we might do for technical data validity include:
For Discover’s enterprise data warehouse, which has a few thousand tables and a few hundred thousand columns, we run upwards of a million technical data quality checks per month in an automated manner. Technical data quality lends itself to automation.
Business Data Quality
Unlike technical data quality, business data quality demands input from a Data Subject Matter Expert(SME)[1] who understands how an application persists data in the backend database. A Data SME understands the business area, processes, and regulations, and can evaluate data quality through the lens of their domain expertise. Continuing with the example Employee dataset, business validation rules might include:
- Alternate ID values must either be a valid Social Security Number (SSN) or a valid Taxpayer Identification Number (TIN)
- Employment Start Date must be 18 years greater than Birth Date
- If the Active Indicator is No, then the Termination Date should not be empty and greater than Start Date
- Each active department must have at least 1 active or inactive employee record
Let’s call these deterministic data quality rules (as opposed to predictive). The rule is set in stone until modified or obsolesced.
Because these data quality rules require domain knowledge, they are hard to scale to the entirety of Discover’s enterprise data warehouse. Data SMEs are hard to come by, and when people change roles, that makes it even harder to preserve knowledge. Business processes change too, which means validation rules need to be constantly added or updated. For these reasons, our business data quality efforts primarily target the most critical datasets and Critical Data Elements (CDEs). At Discover, we constantly strive to do more than what is considered satisfactory. We want excellence. We want that excellence to translate into better data-driven decisions that help our customers achieve brighter financial futures.
Deterministic data quality checks aren’t feasible at scale
Suppose we were to somehow find dedicated Data SMEs to start working full-time on implementing business data quality checks. Some rough estimations will show that even then, at the size of Discover’s enterprise data warehouse, it is not remotely feasible to perform thorough checks across thousands of columns. Let’s take a conservative estimate of 125,000 business data columns to do a Level of Effort (LOE) calculation.
Historically, we’ve seen that it takes about 40 hours for a Data SME to develop, test, and implement a business data quality check for a single column. This takes into consideration the fact that a column’s data characteristics will change overtime, requiring the check to be updated, and accounts for the handoffs required between Data SMEs and engineers to test and implement the check in production. Realistically, we need two to three meaningful checks per column. So, achieving this level of data monitoring for the entire data warehouse demands over 5 million hours[2]! Let’s generously assume we have 100 dedicated Data SMEs working in parallel on this effort. That’s still over 50,000 man-hours per person. If the average Data SME has 2,000 productive hours per year, we’re looking at 25 years to achieve 100% business data quality coverage.
There are ways to somewhat shorten this timeline, perhaps by reusing DQ rules where appropriate, or reducing scope, or throwing more people at the task, but any effort that takes longer than 1 year is likely to be futile in a data ecosystem with ever-changing people, processes, and technologies. The ultimate challenge is that data characteristics are constantly changing, and DQ rules must be adjusted.
Discover is constantly evolving as part of our commitment to customer satisfaction, product innovation and compliance to laws and regulations. As we add new products and features, or when we remove or change existing products, the underlying data changes too. On top of the inevitability of churn in Data SMEs and skyrocketing data operations costs, business data validation with deterministic DQ rules is a quicksand situation—the more you struggle in it, the faster you will sink. It’s better to calm down and think about a novel approach to escape the quicksand.
Predictive data quality with machine learning (ML) replaces manual deterministic data quality
In late 2020, we decided to find a new way to augment and scale our existing data quality monitoring capabilities. Our approach was in line with the saying, “You need a diamond to cut a diamond.” We knew we needed high-quality data for machine learning models to be effective. How about we use machine learning itself to ensure the data is of high quality?
Machine learning can study patterns from historical data and alert Data SMEs if there are anomalies or deviations. The Data SME, in turn, can determine if the alert is a legitimate problem or a false positive (which can also improve the ML model’s future predictions). This combination of automation and human oversight was far more efficient than trying to fight our data quicksand problem by manually writing rules for every potential data issue. In the era of cloud-based data architectures and highly scalable cost-effective compute power, an ML-based data anomaly detection approach makes it feasible to monitor a massive data ecosystem.
While we continue to use deterministic business data quality checks, we now use predictive data quality methods to monitor large swaths of our data. In addition to letting us monitor more tables, predictive data quality checks enable us to find unforeseen problems for which we didn’t think to define deterministic rules in advance. The unknown unknowns. For instance, we might set up a deterministic rule that a personal loan customer’s credit score needs to be greater than some threshold. On the other hand, a predictive rule could alert a Data SME if the average credit score for all personal loan customers has changed by a significant amount, which would be a form of data drift.
There are many ways data could drift or be anomalous, including but not limited to:
- Seeing a zero or null value for the first time in a column
- An increase in the percentage of zeros or nulls in a column
- A higher or lower than average number of records loaded in the latest batch of data, even after accounting for seasonality
- Records from a known segment never arrived in the latest batch
- A value is well outside the typical range of values previously observed for a column
- A metric has increased or decreased over time
- New records did not appear in a table within a historically observed timeframe (Service-Level Agreement [SLA] miss)
- A certain column is usually populated when another column is also populated (correlated data)
This is far too much for any team of Data SMEs to reasonably check themselves, especially for data at Discover’s scale. That’s why automating data anomaly detection has been a game changer so that Data SMEs can focus their efforts on triaging and resolving problems that do arise.
Is it better to build or buy a data quality monitoring solution?
When companies make big pivots, like in our case of a major change to our approach to data quality, an important decision is whether to implement the new strategy completely in-house or work with an external vendor with expertise in that space. At Discover, we started by trying to build a predictive data quality platform from scratch and put an incredibly talented engineering team on the pilot project. The project involved sending email alerts whenever a data element’s values were deviating from the historical norms by a certain threshold. We wanted the solution to perform at scale and have roots in ML. Our platform engineering team rose to the challenge and delivered a working prototype.
We learned something very important when we shared the prototype with Data SMEs to find out if we were on the right track in generating value for them. While anomaly alerts are very helpful, Data SMEs cannot triage alerts as true positives or false positives unless they have insightful data points behind the alert. Decision makers need an explanation of the alert, sample records, and most importantly a user-friendly interface to make sense of it all. The Data SME self-service experience must be remarkably simple.
While our prototype gave us confidence in taking a predictive approach to scaling data quality, we also realized that it would take at least 6 months to a year to build the rich User Interface (UI) that would provide the User Experience (UX) expected. We didn’t have people with the requisite UI/UX skill set on our team. Not to mention, the investment needed to build and maintain such a complex product within a reasonable timeline gave us a pause with the build in-house approach.
Given these limitations, we decided to explore vendor products that had the following characteristics:
- Strong ML & Artificial Intelligence (AI) foundations for predicting data quality issues at scale
- Rich UI for enabling self-service implementation of data quality checks
- Rich UI for monitoring and explainability of data anomaly alerts
- Rich UI for disposition and remediation tracking of data quality issues
- Role-based access controls and enterprise-grade identity and access management (IAM)
- Scalable to handle petabytes of historical data with terabytes of incremental inflow
We considered several leading and emerging data quality product vendors. Ultimately, we went with Anomalo as the best product for our needs.
Why did Discover choose Anomalo as its enterprise data quality platform?
Having decided to procure a vendor data quality platform instead of building our own, we started by putting together our capabilities wish list. The capabilities we were looking for fell into a few different themes of functional and non-functional requirements, each of which Anomalo excelled in, making it our eventual pick.
The first and most important theme is the ability to automatically monitor data quality in an adaptive, turnkey manner. Other aspects like UX mean very little if the platform can’t identify data issues reliably. Then, does the data quality platform use predictive monitoring techniques rooted in ML? Is it capable of handling Discover’s ever-increasing volume of data?
We wanted a platform with the following characteristics with respect to speed and scale:
- The ability to configure unsupervised data quality monitoring within 10–15 minutes for a dataset irrespective of how wide it is (table has 10 columns or 1000 columns) or how deep it is (100K rows or 100 billion rows)
- Scalable anomaly detection for thousands of datasets, hundreds of thousands of columns, and billions of rows
- The ability to provide a basic out-of-the-box data profile for multi-terabyte datasets
- Efficient data monitoring algorithms that are optimized for cloud compute
We still cared deeply about UX, and the following qualities were essential to our team feeling comfortable with Anomalo with respect to self-service and usability:
- The ability for Data SMEs to self-serve using an elegant UI. Data SMEs should not be dependent on data engineering teams
- A calendar view of previously run data quality checks
- Plain-English explanations and rich visualizations of why an alert was triggered
- Support for a plethora of user-defined validation rules with point-and-click templates (no SQL knowledge required)
- An executive-level dashboard for data quality coverage and overall data health
Furthermore, we prioritized alerting capabilities so we could trust our data quality platform to proactively notify the right stakeholders when data quality issues do occur. Alerting features we wanted included:
- Support for alerts via multiple notification channels (e.g., Teams/Slack, e-mail) and ability to select the notification channel at a DQ check level
- Alerts that link to examples of both anomalous and non-anomalous data records
- The ability to (un)suppress an alert based on triaging by Data SMEs
- The ability to annotate an alert for future reference
We also looked for the following table stakes technical features:
- Automatic checks for data freshness and data volume anomalies keeping in mind seasonal patterns
- Rich API support for the entire platform
- Integrations with cloud databases such as Snowflake, Google BigQuery, AWS Redshift, Postgres, etc.
- Integration with enterprise data catalog products such as Alation
The capability list could easily go on. Hopefully this highlights few major advantages of opting for a solution like Anomalo over trying to build your own and achieving only a subset of these features.
We went with Anomalo because of the company and its team, in addition to the product. The company is fully committed to delivering a successful implementation and quick ROI. We started with a 3-month trial period and were extremely impressed with Anomalo’s response times to accommodate new feature requests to suit Discover’s specific use cases. We also trusted Anomalo’s team because of their experience as data practitioners, with founders who were data science leaders in large data-driven organizations.
Anomalo’s approach to data quality monitoring emphasizes predictive, scalable detection efforts, but doesn’t neglect deterministic rules, which still matter to the Data SMEs here at Discover. Anomalo groups its monitoring techniques into 3 buckets: validation rules, metric anomalies, and unsupervised machine learning. As the following graphic highlights, these buckets range in terms of how much user input they require, which allows us to use high-input methods for our most critical datasets and less taxing methods for the bulk of our data.

Discover has been using Anomalo in production for nearly 2 years with flourishing adoption and is continuing to integrate the platform across our entire organization. We are confident that Anomalo will enhance our ability to monitor data quality at scale and with less manual effort.
Want to see how Anomalo can help your organization? Sign up for a free demo today.

Categories
- Case Studies
- Industry - Financial Services
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Get Started
Meet with our expert team and learn how Anomalo can help you achieve high data quality with less effort.