Chapter 7: Integrations multiply the power of your autonomous data tools
June 3, 2026

Welcome to “Use AI to modernize your data quality strategy,” a series spotlighting insights from our O’Reilly book, Automating Data Quality Monitoring. This post corresponds to Chapter 7: Integrating Monitoring with Data Tools and Systems.
Most enterprises use many tools to manage their data. The more deeply your automated data monitoring service integrates with your data tools and systems, the more valuable that monitoring is to your teams.
That’s the topic of Chapter 7 of Automated Data Quality Monitoring, our O’Reilly book, and it’s becoming even more impactful as self-driving data comes onto the scene. Anomalo’s autonomous agentic AI unlocks hands-off monitoring for more of your enterprise, and that impact is multiplied by thoughtful, robust integrations.
Which integrations matter most?
Ideally, data quality monitoring is integrated at five points throughout the data stack:
- Data warehouses
- Data orchestrators
- Data catalogs
- BI (business intelligence) dashboards
- MLOps (machine learning operations) tools
Data warehouse and data orchestrator integrations are table stakes. Your data monitoring simply won’t work without them—data needs to be monitored at various points in its journey, not just when it’s at rest in its final data warehouse location. The other three integrations aren’t strictly required for monitoring, but will add significant value to your data team by providing information about the current state of the data within other tools and workflows.
Data warehouses
Data warehouses and data lakes are the canonical home for at-rest data. They ingest data from various sources, and then feed it downstream to data consumers such as ML models and analytics dashboards. Because this is the core home of your data, warehouse integration is the foundation of your data quality monitoring platform. Without this type of integration, there’s nothing for your platform to monitor!
However, many enterprises have multiple data warehouses, perhaps even spanning both cloud and on-premises. Wherever important data lives, you must have an integration, but this isn’t as easy as checking a box. Each warehouse tends to have its own quirks, such as specific SQL requirements, so you will need to be sure that your solution’s integrations are efficient, reliable, and accurate.
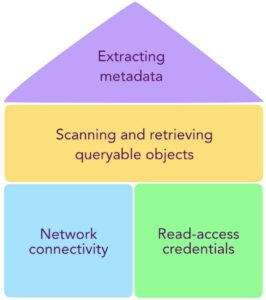
There are four basic building blocks for a successful data warehouse integration:
- Network connectivity, which may require IP allowlisting
- Read-access credentials on the database you need to monitor (ideally with a dedicated service account)
- A system for scanning the data warehouse and retrieving a list of queryable objects
- A system for extracting metadata for table observability and root cause analysis
We recommend running the scan and extraction daily, though your situation may benefit from a manual refresh trigger.
With the power to examine data quality in a data warehouse comes the responsibility to keep any private information in that warehouse secure, including personally identifiable information (PII). You may have compliance and legal requirements around the data to which you have access. In addition to regulatory requirements, SOC 2 certification is the industry standard that’s expected of data quality monitoring systems.
When considering privacy and security, take your agentic tools into account. How are agents interacting with your data? How is conversation data being stored and used? Make sure you’re comfortable with the answers to these questions, and be wary of third-party agents that aren’t native to your data monitoring tool.
Data orchestrators
Data orchestrators automate and schedule the process of bringing raw data from e-commerce systems, third-party APIs, and so on into the warehouse. Closely related are extract, transform, and load (ETL) processes.
We highly recommend integrating your data quality monitoring platform with any data orchestrators you may be using. This is where you’ll catch issues with your incoming data feeds, for instance. You could theoretically run monitoring only on the warehouse layer, but you miss the chance to catch many issues earlier. If you’re leveraging autonomous agentic data, your agents will also benefit from any additional context available through an orchestrator integration.
Because orchestration (and ETL) can take many steps, you should be able to monitor data at any point in the data journey without much friction. Your monitoring tool should also support at least three types of functions: running checks, knowing when they’re complete, and validating them.
Data catalogs
These tools, from companies such as Alation and Atlan, provide a centralized view of data assets, metadata, and their relationships. They make it easier to discover, understand, and use data across an organization.
When integrating with a catalog, think bidirectional. You’ll want to display data quality status within the catalog, as it’s crucial information for anyone interested in a dataset. But also consider deep-linking to the catalog from your data quality monitoring tool. This can give you additional context to help determine which data might require extra monitoring attention.
BI tools
Many companies use business intelligence (BI) tools like Tableau and Power BI to create dashboards and analyses. As business decisions are very often based on the data analyzed here, it’s quite useful for the audience to know whether they can trust the data. An A-OK gives them confidence; any flags let them know to not take what they’re seeing at face value.
This integration might be on the easier side, as many BI tools have APIs to support data quality alerting. You can also use BI tools as input to your data quality monitoring, by treating KPIs as key metrics to track.
On the other hand, BI tools can have a bit of a learning curve. Consider asking your team members for input when building this integration. If some non-technical users feel locked out of BI reporting, natural language chats with autonomous data agents may open up a world of analytics possibilities!
MLOps tools
Tools such as Amazon SageMaker and Metaflow are useful for automating, standardizing, and improving processes that support ML. They typically monitor metadata such as model performance, latency, and uptime.
In Chapter 2, we explained that observability is a quick and easy way to make sure a table is receiving timely and appropriately sized inputs. However, it won’t let you know if the contents of those updates can be trusted. Similarly, on their own, MLOps will let you know that systems are working, but not whether they’re working off of good data.
Data quality monitoring within MLOps tools should be able to warn data scientists that models need to be retrained because underlying data is either inaccurate or missing. You could also use your data quality monitoring system to directly monitor model performance and the accuracy of model predictions.
Since we wrote the book (not even very long ago!), much has changed in the realm of AI. From unstructured data monitoring to the new frontier of self-driving data, there’s a lot of progress to be happy about. Perhaps we’ll write another book on these topics someday; for now, we’ll point out that AI tools are only as good as the context they’re given.
The lowdown on integrations
All these integrations may sound like a whole lot of work, but if you’re investing in a data monitoring solution, you’ll find that integrations both save time later on and improve user experience in the short term. If you’re buying a tool from a vendor, ensure that they provide these integrations and that setup is straightforward.
In the next and final chapter, we’ll talk about deploying automated data quality monitoring, both from a technical and organizational perspective.
Categories
- Book
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Ready to Trust Your Data? Let’s Get Started
Meet with our team to see how Anomalo transforms data quality from a challenge into a competitive edge.