Why Data Quality Monitoring Is a Must-Have for Financial Services
November 14, 2023
AI and machine learning models can be instrumental in a variety of financial services applications, such as fraud detection, liquidity management, or customer churn prediction (to name a few). But without data quality monitoring, the use of AI can backfire by creating risk for businesses and their customers.
High-quality data is the foundation of any effective and impactful machine learning solution. If models are presented with unstable inputs that vary from the historical data they were trained on, they will behave erratically. Advanced data quality monitoring techniques, such as unsupervised machine learning for anomaly detection, are the key to ensuring reliable models that can uphold regulatory requirements.
Why traditional data quality monitoring won’t cut it
Historically, businesses have enforced data quality using predefined validation rules. This quality control method functioned well enough in the past, when organizations were dealing with data that was relatively low in volume and updates to datasets were introduced at a manageable pace.
In recent years, the way the financial services industry uses data has completely changed. Consider the scale and speed institutions are required to operate at, the variety and complexity of the data at hand, and the implications of their data-driven decisions, especially when machine learning is involved.
When it comes to modeling for financial services applications, traditional data quality monitoring won’t cut it because:
- Data quality must now be ensured at scale. Finserv models can depend on petabytes of data and financial institutions might utilize thousands of tables. This is simply too much data to assess with predefined, hard-coded rules.
- Many unknowns can’t be predicted. Data quality rules won’t be able to anticipate unforeseen and nuanced issues that can occur deep in the structure of the data, such as changes in how data is represented or reported by providers.
- Data used in modeling should be held to a higher standard. Traditional monitoring methods allow issues to slip through the cracks. Now that financial services providers are embracing machine learning, data quality is even more important. Data quality issues can lead models to fail in unexpected ways that are very difficult to detect and fix.
How data quality issues can break finserv models: Example
To understand this, imagine a hypothetical scenario (based on a true story) in which a bank wants to improve their liquidity management by building a model that predicts customer deposit behavior. To train the model, they use a time-series dataset logging customer behavior and money movement. This dataset contains Standard Industrial Classification (SIC) codes that correspond to businesses, categorizing the industries to which companies belong.
Now let’s say that some of the SIC codes changed—perhaps this was due to a re-release from the external provider, altering the mapping between SIC codes and assets by recategorizing certain businesses. Although these new SIC codes would still be considered valid, the mapping change would be a problem for the business’ machine learning models, which operate under the assumption that the same assets will always map to the same codes. If this is no longer true, it becomes impossible for these models to conduct a reliable apples to apples comparison between different points in the time-series, and model performance falls apart.
Traditional data quality rules would likely be able to detect invalid SIC codes. But when the data quality issue has more to do with complex relationships within the raw data as opposed to the validity of a single record, more advanced techniques are required. Fortunately, there is a better way.
Unsupervised machine learning for anomaly detection: how it works
Unsupervised machine learning for anomaly detection is an advanced technique that allows for scalable data quality monitoring and the detection of “unknown unknowns.” This innovative method automatically detects material adverse changes happening in the data itself, identifying clusters of data that are potentially problematic. Examples include sudden increases in null values, distribution changes, segments of data that have disappeared, and even columns whose relationship to one another has changed. Beyond simply identifying anomalous data, unsupervised learning also makes it easier to trace common possible root causes, enabling users to detect and resolve issues faster—all while requiring fewer resources.
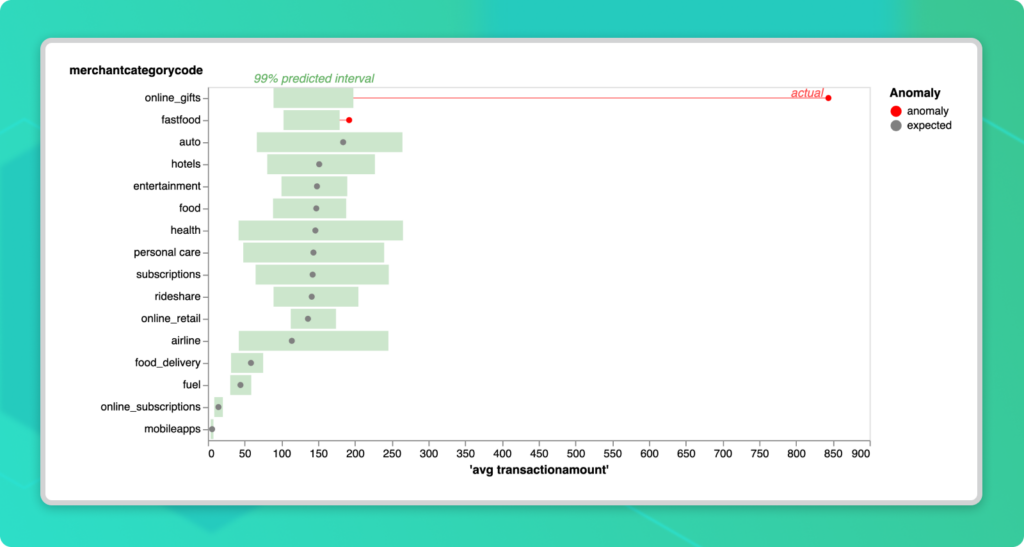
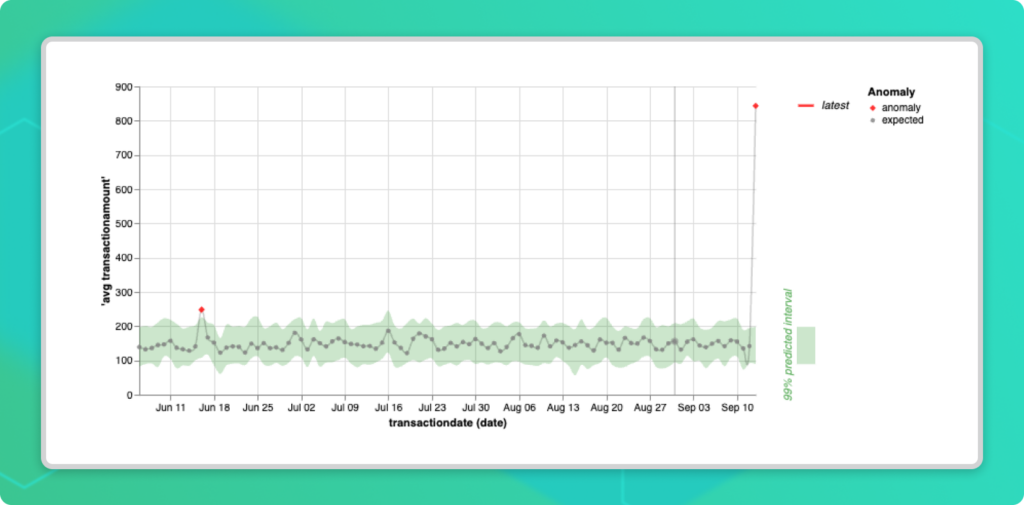
Anomalo is a comprehensive data quality software that uses unsupervised learning techniques to enable high-quality AI outputs. Anomalo trains a model using samples from the most recent day of data in addition to several past lookbacks in the time-series. The system can then determine if there is something unique about today’s data, including deep aspects like relationships between columns, that might signal a data quality issue.
Anomalo’s algorithms also highlight which columns and records are most closely associated with the change, helping users identify the root cause. In the case of the updated SIC codes, Anomalo would have been able to detect a sudden and significant anomaly in the distribution of codes among certain records. This would have almost immediately indicated a change in the mapping, allowing table owners to promptly implement a fix.
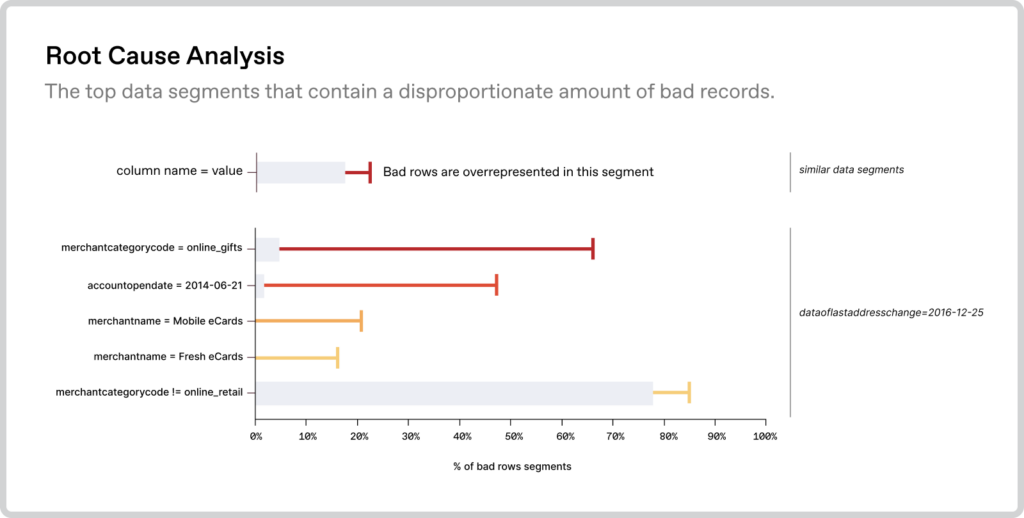
Unsupervised learning is also uniquely well-equipped to handle “unprecedented” data quality issues. With validation rules, we can only protect ourselves from problems we already understand. But Anomalo is able to observe patterns with minimal guidance and learn what constitutes “normal” data. That way, when data points deviate from the norm based on past observations, Anomalo automatically alerts data table owners to take a closer look and get ahead of issues that could have downstream consequences. This means that not only is Anomalo’s approach to data quality monitoring more effective and reliable, it’s also much more efficient both in terms of time and resources.
Benefits for financial services applications
Data quality monitoring solutions that leverage unsupervised machine learning offer several benefits to businesses in the financial services space.
Performance
As we saw in the previous section, an unsupervised learning-based data quality monitoring system can be instrumental in rapidly detecting meaningful changes. This is especially important when abnormal data can negatively impact high-stakes model performance. In the financial services space, models are often used to make (or even automate!) critical financial decisions, significantly impacting how customers interact with your business.
Understanding + Calibration
Although anomalous data is not always indicative of an error, it’s important to be aware of and understand further. For instance, a change in the dataset logging customer behavior may be caused by a trend in how customers are interacting with a new feature, rather than a data quality issue. But it’s still essential to be aware of this change in the data because of how it can affect a model. Models are trained on historical inputs, and these kinds of “data drifts” may indicate a need to retrain or recalibrate the model on updated information to maintain performance.
Regardless of whether anomalous data is accurate or inaccurate, we should think of the insights offered by data quality monitoring as instrumental in building our understanding of the bigger picture of the dataset—and the models that are built on top of it. This allows more room for capturing nuance and complexity that would not be possible with the rigid rules of traditional data quality monitoring. So beyond simply identifying issues, our platform enables clients to better understand their data.
Compliance
Financial services providers are under strict requirements to report certain data to regulatory bodies. Mistakes in this critical data can result in additional auditory scrutiny and even fines and penalties. With automated data quality monitoring in place, companies can rest easier knowing that the data sets they are reporting externally are being continuously tested for any errors and inconsistencies.
Additionally, data quality monitoring can be useful for model validation. Validators look for evidence that models are built on high-quality data. Thus, data quality monitoring tools, especially those that provide a visual interface, can make validators’ jobs much easier.
Monitoring should work with your data organization
Before implementing a data quality monitoring solution for your business, there are several factors to consider, many of which go beyond the technologies themselves. At Anomalo, we work seamlessly to address these considerations, tailoring the specific implementation and partnership details to each customer we work with.
- Ownership must be established at the table level to ensure that issues that are flagged by the system can be promptly investigated and addressed. Anomalo promotes this by offering a built-in triage function allowing users to easily assign tasks and track progress. For this to work, notifications must be strategically and intelligently configured to minimize alert fatigue and keep manual intervention to a minimum. Anomalo uses several false-positive suppression techniques to ensure alerts are targeted and meaningful, which is especially important for large datasets such as transactional data.
- Observability is a fundamental aspect of data quality monitoring, capturing the overall health of the data as a whole. It involves checking things like whether or not data has arrived on time, at the right volume, and in the correct format relative to past data points. Table observability is built into our product and is easy and cost-effective to set up for the entire data warehouse, helping data engineers better spot these kinds of issues and determine if and when pipelines may need to be fixed.
- Versatility ensures that all data quality monitoring needs are met. Although unsupervised learning is certainly more comprehensive, traditional techniques like validation rules and metric-specific monitoring can still be helpful due to their more targeted approach. Our platform makes it easy to add manual rules based on subject matter expertise and track high-priority metrics, such as key performance indicators, in addition to leveraging unsupervised learning for anomaly detection across the data at scale.
- Integrations with orchestration and data management tools should be seamless in order for the data quality monitoring system to function smoothly. Anomalo supports both legacy and modern cloud data warehouses and offers robust integrations with catalog providers, and our partnership with Snowflake is particularly relevant due to its Financial Services Data Cloud.
- Privacy and security are growing concerns when it comes to working with data, which is why many businesses are opting for developments inside their virtual private cloud (in-VPC) instead of centrally hosted software as a service (SaaS). While SaaS is the simplest model, VPCs are the only way to retain full data ownership. We offer both options for our unsupervised learning data quality monitoring platform, allowing customers to decide which approach best suits their needs.
- Governance establishes best practices and standards for managing data as a strategic asset. Anomalo is part of the EDM Council, a leading global trade association with over 350 member firms, confirming our commitment to advancing data management practices and promoting data quality in regulated industries.
How Anomalo can help your business
As we’ve seen, traditional data quality monitoring doesn’t hold up in a present day context, especially when machine learning and financial services applications are in play. Unsupervised learning for anomaly detection is the cutting-edge solution that will ensure these critical AI solutions are not only functional but also highly trustworthy, efficient, and effective.
To learn more about how Anomalo can help your business modernize its approach to data quality monitoring, make sure to request a demo.
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Get Started
Meet with our expert team and learn how Anomalo can help you achieve high data quality with less effort.