Agents
THE STANDARD FOR COMPLIANCE READINESS AND DATA CONFIDENCE
Enterprise Data Quality for Financial Services
Data is the lifeblood of every decision, transaction, and report in banking, insurance, and capital markets. From regulatory reporting to AI-driven risk and fraud models, data integrity underpins performance, compliance, and reputation. Yet legacy systems, siloed data, and rapid AI adoption make accuracy harder than ever. Poor data quality creates not just inefficiency but real regulatory, reputational, and financial risk.
Trusted by Industry Leaders





















Key Benefits
Enterprise data quality for financial services
Better Risk Management and Fraud Detection
Detect shifts in fraud signals, risk levels, and customer behavior. Anomalo reconciles internal and third-party data across distributed systems to surface early indicators of problems.
More Efficient Underwriting
Ensure underwriters never rely on stale, incorrect, or corrupted third-party bureau data, such as faulty credit scores or missing attributes.
Optimized Quant Research and Trading Analytics
Shift teams from firefighting to analysis. Anomalo helps ensure signal data, market feeds, and factor model inputs remain stable and reliable to reduce model noise and improve performance.
Better Trading Strategies
Your ability to craft successful trading strategies is dependent on the accuracy, quality, and timeliness of data you receive. With data quality maintained automatically and consistently, your strategies will be better-informed and more likely to succeed.
Data Sharing With Confidence
Validate match rates between internal customer records and augmented third-party datasets, ensuring that marketplace and partner feeds are complete, accurate, and safe to ingest.
Stronger Anti-Money Laundering (AML) and Know Your Customer (KYC) Monitoring
Anomalo tracks drift in customer profile information, transaction behavior, sanctions lists, and case review datasets to enable early detection of suspicious activity.
Why Data Quality Is Essential for Financial Services
In financial services, poor data quality isn’t an inconvenience; it is a source of regulatory, financial, and reputational risk.
75%
of financial services executives say complex regulatory requirements are a top concern
Compliance Gaps Increase Regulatory Exposure
Regulators expect complete, accurate, and timely data across risk, capital, liquidity, AML, and model reporting. Inconsistent and incomplete datasets drive errors in reporting under Basel III, CCAR, and suspicious activity standards, potentially contributing to negative findings and fines.
Data Errors Create Decision Blindspots
Bad or drifting inputs distort risk scores, credit decisions, trading signals, and pricing models. 75% of banks would prioritize improving governance if they were to restart their GenAI implementation.
81%
of banking data consumers pointed to a lack of quality as a data usability challenge
$136M
fine imposed on a financial services institution for insufficient progress on regulatory reporting
Trust in Data Is Dropping
Executives lose confidence when leaders or regulators find issues first. Many teams can’t detect late or inaccurate data inputs, can’t resolve issues fast enough, or are overwhelmed by alerts. This erodes trust in analytics, models, and operational dashboards.
Legacy Approaches Can’t Keep Up
Rules-based checks and metadata-only observability tools fail to detect the full range of anomalies within complex financial datasets. They create a costly “data quality doom loop” of writing more rules, chasing alerts, and reacting after the fact.
93%
of risk leaders said it is imperative that the banking industry address the increased speed of risk
Protect Revenues, Reduce Risk, Seize Opportunities, and Ensure Compliance with Proactive Data Quality
Trusted data is foundational for regulatory confidence, model accuracy, trend detection, fraud prevention, and customer trust.
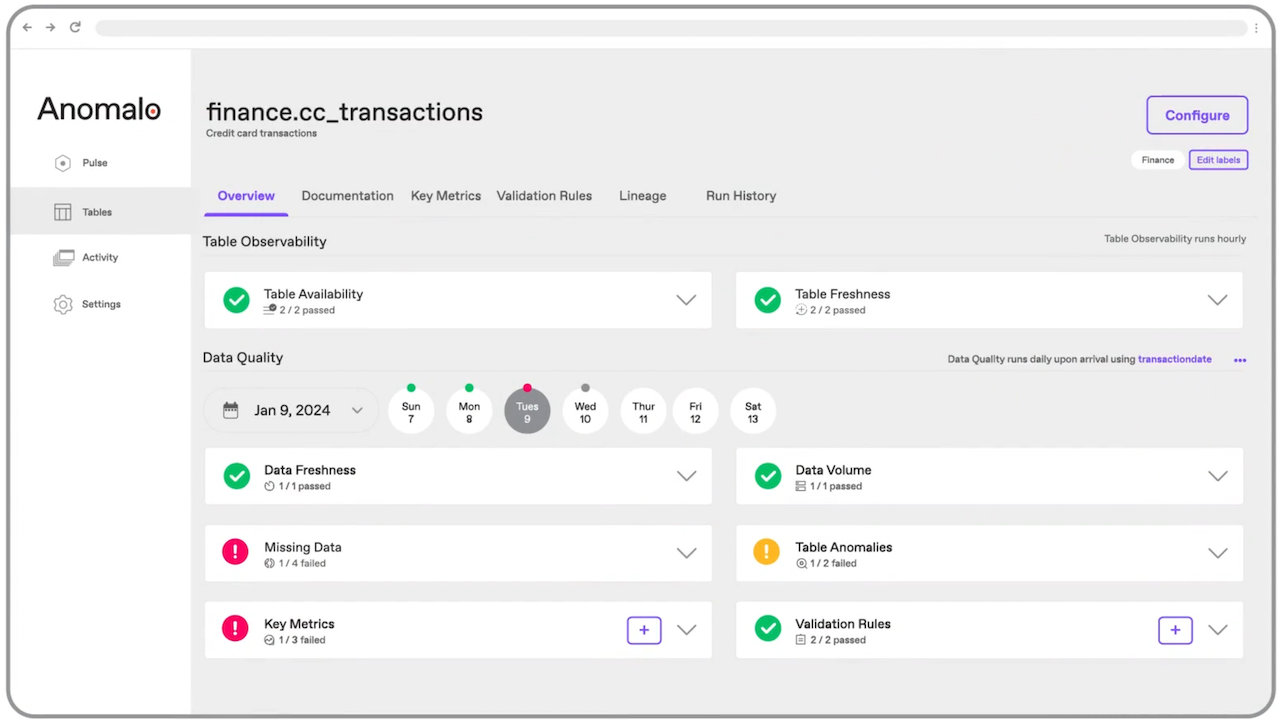
AI-Native Monitoring that Adapts to Your Business
Anomalo automatically learns common patterns in financial datasets, from transactions, loan files, and risk calculations, to anti-money laundering (AML) profiles, customer records, vendor feeds, and unstructured documents. Anomalo detects exceptions as soon as they appear. No rules to write. No thresholds to tune. Just continuous, ML-driven detection.
Unlock Confidence Across the Entire Data Estate
Automatically identify inconsistencies across large, fast-changing transactional, risk, and regulatory datasets. Anomalo surfaces completeness issues, reconciles mismatches, and flags emerging changes—supporting CDMC compliance and audit-ready traceability.
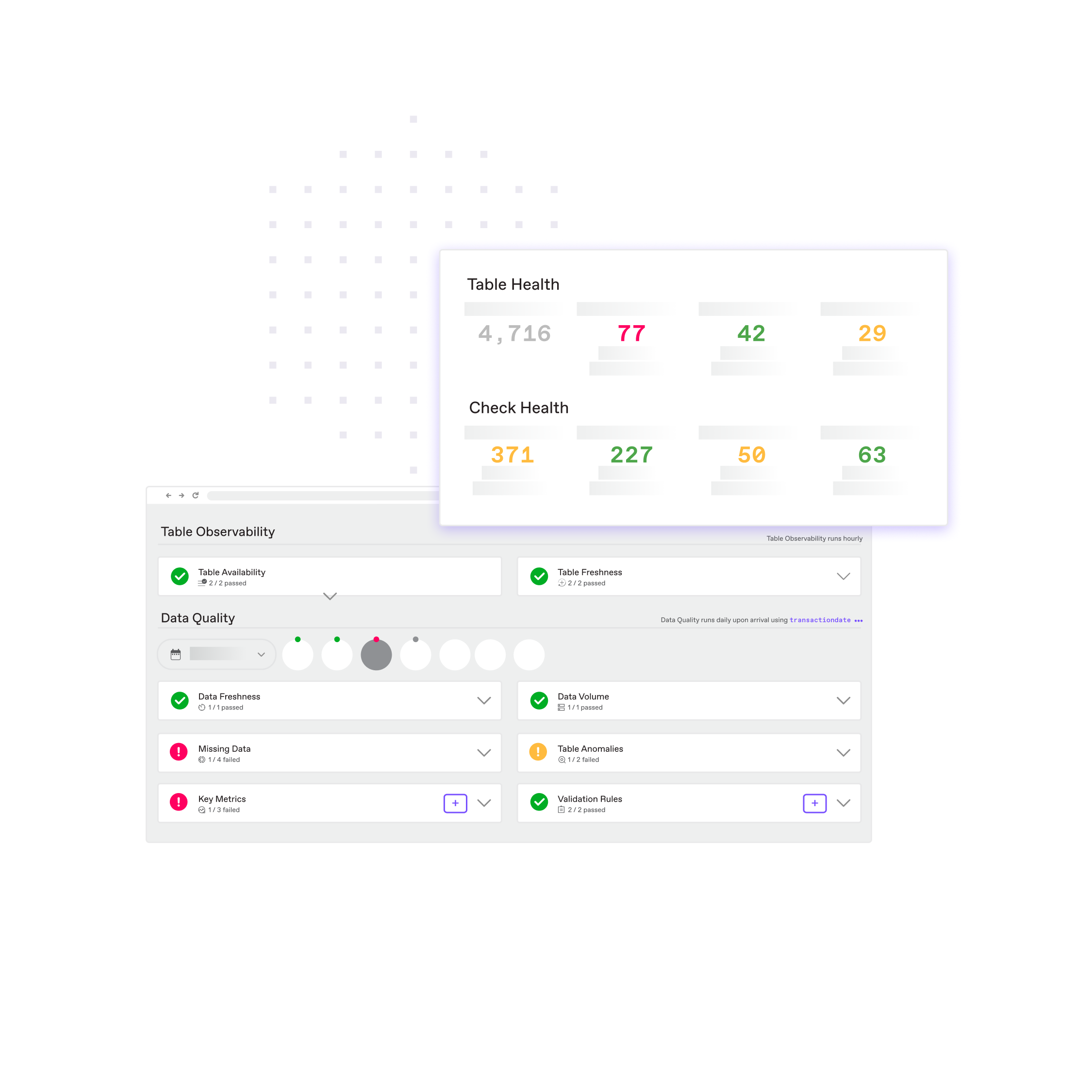

Seamless Integration with Your Data Ecosystem
Financial institutions move fast—and so does Anomalo.
Anomalo features native integrations with BigQuery, Databricks, Snowflake, and key cataloging and workflow tools such as Alation, Unity Catalog, Jira, ServiceNow, Slack, and more, enabling teams to monitor critical data on a minute-by-minute basis.
Proven Scale and Enterprise-Grade Trust
Anomalo powers data quality for some of the world’s most demanding financial services organizations, monitoring thousands of tables, hundreds of thousands of columns, and petabytes of data.
SOC 2 Type II certification and compliance support for your organization’s governance standards. In-VPC deployment means data never leaves your systems. Sophisticated role-based access controls enhance your security posture.

Our Customers
What Customers Say
“We selected Anomalo to fully automate the basis of our data quality monitoring because their machine learning and root cause detection technology identifies late, missing, or anomalous data across our petabyte-scale cloud warehouse.”
Keith Toney
EVP & Chief Data & Analytics Officer
“Anomalo has found more data quality problems with its out-of-the-box, turnkey solution than Nationwide’s 3,000 rules.”
Director of Enterprise Data Governance
Build Regulatory-Ready, Trusted Financial Data
Get our data sheet to learn how leading financial services organizations use Anomalo to strengthen data quality, reduce risk, and accelerate confident decision-making.