How Anomalo Detects Data Issues in Airflow Pipelines
December 15, 2022
Our mission at Anomalo is to automatically detect data issues and understand their root causes, before anyone else. With the modern data stack involving numerous services working together, there are all kinds of ways for things to go wrong, ranging from data delays to invalid information. Anomalo serves a critical role as a data observability and quality platform to detect problems, alert the right people, and facilitate a speedy resolution.
The many moving parts of the data stack also necessitate an orchestration tool to configure automated pipelines. Apache Airflow is a popular choice that enables data engineers to manage workflows in the form of DAGs (directed acyclic graphs). DAGs correspond to sequences of tasks in which each step may have one or more dependencies. Airflow provides operators to define these tasks; for example, SimpleHTTPOperator sends an HTTP request.
With this latest integration, we’re introducing native Airflow operators for Anomalo so that checking data quality can be automated alongside the rest of the modern data stack.
Integrate Anomalo into your existing Airflow workflows
Many organizations already use Airflow to manage ETL (extract, transform, load) pipelines. Airflow workflows are fully customizable since engineers define their own DAGs, so alternative models like ELT are also viable. We’ll continue to use ETL in this example, but note that the new Anomalo operators are compatible with a wide array of data pipelines.
Under the ETL model, the first step is to extract data from the appropriate sources. Perhaps unstructured data gets ingested both from user logs and a 3rd party SaaS tool. Each of these could be independent tasks in the DAG. After completing both tasks, data can be transformed into the desired format before finally being loaded into the desired place for storage. Airflow automates this entire process and can even repeat it on a schedule.
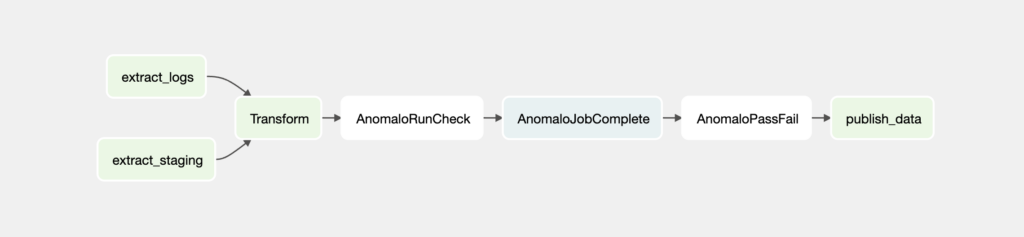
What happens if the data is incomplete or anomalous? The new Anomalo operators can fit right into the ETL workflow to watch for these cases and flag issues immediately, preventing low-quality data from continuing through the pipeline. We have two new operators: one runs Anomalo’s suite of checks for a given data table and the other takes in a list of checks that must pass and can stop the Airflow workflow if something failed. For a full rundown, check out our repo on GitHub.
Airflow gives lots of flexibility with respect to how Anomalo slots into a workflow. In the diagram above, you can see how it’s possible to run Anomalo checks after the transformation step of the pipeline. An alternative DAG could place the checks further upstream, right after data is extracted from each source. This way, it might be easier to identify an issue coming specifically from the user logs, for instance.
It’s now easier than ever before to incorporate Anomalo’s advanced machine learning right into your regular workflows so that you can be confident of your data quality in every layer of your stack. With Anomalo’s monitoring and alerts, you’ll know when there’s an issue and will be able to easily pinpoint where the problem is coming from. If you’re new to Anomalo, we’d be more than happy to answer your questions and arrange for a demo.
Categories
- Product Updates
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Ready to Trust Your Data? Let’s Get Started
Meet with our team to see how Anomalo transforms data quality from a challenge into a competitive edge.